第 1 章 绪论
1.1 研究目的和意义
人们在生活中通过视觉来获取各种各样的信息,而图像是人们获取大量的信息的一个重要来源。伴随着计算机的蓬勃发展和迫切快速处理图像信息的需求,人们开始使用计算机对图像进行处理。但是由于诸多原因如硬件设备或者环境恶劣导致图像的分辨率降低和信息量减少,所以提高图像的分辨率是图像增强领域中一个非常重要的课题。
超分辨率是通过软件或硬件的方法将一个给定的退化的低分辨率图像重建成高分辨率的图像的技术。由于硬件来改善图像的质量代价很大,所以一般通过软件的方法来重构图像。目前,随着超分辨率重建技术的深入研究,该技术在许多领域中具有重要应用价值,如人脸识别,视频质量重建,医学影像处理和遥感卫星图像处理等。在人脸识别领域,由于人脸分辨率低,容易出现误检的现象,可以通过超分辨率技术提升图像质量帮助后续的人脸识别网络达到更好的精度;在视频质量重建方面,一些视频的质量较差,可以通过超分辨率技术恢复出高质量的视频;医学图像处理方面,由于医疗设备的问题获取的医学图像不够清晰,通过超分辨率技术帮助医生识别出人眼不能够辨别的病灶区域;卫星图像处理方面可以利用图像超分辨率识别出低分辨率的物体或者获取更清晰的地理细节。因此,研究超分辨率在生产生活中具有重要的意义。
.....................
1.2 国内外研究现状
1.2.1 传统超分辨率方法的研究现状
传统超分辨率方法是指恢复高分辨率的图像利用传统的算法,而不是深度学习的算法,其主要分为基于重构的超分辨率和基于样本学习的超分辨率。
(1) 基于重构的单幅图像的超分辨率算法。
基于重构的超分辨率算法主要有两种方法分别是频域法和空域法两个算法。频域法是在频域上分别对低分辨率(Low-Resolution,LR)和原始的高分辨率图像(High-Resolution,HR)进行傅里叶变换操作,然后在频域的角度上对两者建立起线性的关系,进而恢复图像的分辨率。频域的方法大多认为低分辨率的图像中不存在各种模糊和噪声,所以被认为是理想不现实的图像退化模型,导致该方法的限制性很大。频域法重建过程相对来说较为简单并且运行的速度相对较快,但是很难去处理复杂场景下的图像退化问题,也相对较难嵌入其他提高效果的先验信息和知识。通过研究,可以采用如小波变换[1][2],离散 DCT[3]变换等改进算法弱化图像中的模糊和噪声,加快算法的速度,有效改善图像恢复的质量。空域法是对影响图像成像效果的空域因素进行分析,比如运动模糊和噪声等因素。所以这种方法更接近实际的应用场景。该方法常用的算法主要包括凸集投影法(POCS)[4],迭代反投影法(IBP)[5],最大后验概率方法[6][7]等算法。
(2) 基于样本学习的图像的超分辨率算法。
基于样本学习的超分辨率算法主要通过利用嵌入的先验知识来训练成对的图像数据集,并在 LR 和 HR 之间建立相应的映射,学习到函数关系。之后利用这种学习到的线性或非线性的函数恢复出 LR 图像中退化丢失的高频特征,从而实现对LR 的重构。此方法主要有构建用于训练的数据集对、特征间的学习和高频信息的重建三个步骤。构建训练成对数据集主要是通过对 HR 图像进行降采样获取相对应的 LR 图像;特征间的学习是为了学习 LR 和 HR 图像之间线性或者非线性的函数关系;高频特征信息的重建则依据学习到的函数关系从 LR 图像中重构恢复出HR 图像。空域法根据训练样本的数据库的出处及特征域的匹配程度的不同,可分为基于图像自相似性的方法[8][9]、基于邻域嵌入的方法[10]和基于稀疏表示的方法[11]。在图像自相似性的方法中,训练数据的样本主要来源是输入图像自己本身。与自相似性不同,在邻域嵌入和稀疏表示的方法中,训练数据的样本和输入的图像关系不大,主要出自于外部的数据源。
..........................
第 2 章 背景知识和相关工作
2.1 引言
本章主要是介绍了超分辨率的退化和重建过程,还介绍了神经网络基础、卷积神经网络和残差网络的相关知识。除此之外,还说明了需要的一些技术如主成分分析技术和延展策略。为了方便读者能够阅读并理解后续的章节,本章对超分辨率所涉及到的知识,层序渐进的进行说明。在形成一个完整的网络结构中,每个基础模块和技术都是为了解决某一个的问题,这些模块的结合和技术的应用最终会实现一个泛化能力强的网络模型。
神经网络虽然解决了单层感知机计算能力差的问题,但是它在反向传播的过程中会出梯度消失和弥散的问题,因为反向传播会使用 Sigmoid[53]或 Tanh[54]等连续函数作为激活函数,所以这种损失函数随着层数的加深会出现一些诸如梯度消失和弥散的问题,导致在回传的时候接受不到有效的训练信号。为了克服梯度消失和弥散的问题,ReL U[55]函数基本取代了 Sigmoid 函数,在这之外,还引入了残差网络进一步解决了梯度消失的问题,并且加大了网络的深度。在网络训练中,全连接的深度神经网络结构会导致网络的权重参数数量的极速膨胀,导致网络表现出过拟合的现象,容易得到局部最优解,无法获取到全局最优的权重参数。
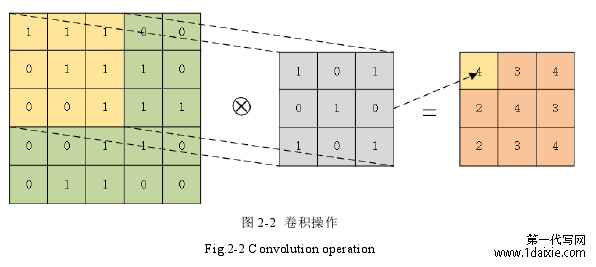
图 2-2 卷积操作
2.2 深度学习相关理论
2.2.1 神经网络及卷积神经网络
卷积神经网络(Convolutional Neural Networks,CNN)主要包含卷积层、池化层和全连接决策层等多种模块。在计算机视觉方向应用广泛并展示了卓越的性能,常用来分析处理视觉图像。如图 2-1 所示是一个卷积神经网络的架构, 卷积层的任务是负责提取图像中的局部特征;池化层主要用来降低网络参数的数量,提取重要的特征并且缓解过拟合;全连接层主要任务是进行分类,输出结果;最后会先将多维的数据进行拉伸,也就是把高度、宽度和通道数为 , 和 的数据压缩成长度为 × × 的一维数组,然后再与全连接 FC 层连接,最后经过 Sigmoid 进行分类。
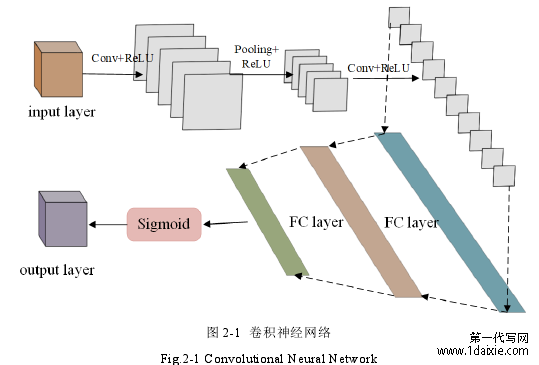
图 2-1 卷积神经网络
...............................
第 3 章 基于模糊核估计与注意力机制的图像超分辨率 ................... 21
3.1 引言 ................................ 21
3.2 问题的提出 ................................... 21
3.3 设计思路及整体架构 .................................. 22
第 4 章 实验结果及分析 ................................... 31
4.1 引言 ............................................ 31
4.2 实验数据及训练环境 ............................... 31
总结与展望 .............................. 47
第 4 章 实验结果及分析
4.1实验数据及训练环境
初始的输入训练数据包括三个部分:高分辨率图像,估计的模糊核,人脸关键点图。首先,高分辨率数据集主要包括四个子集,Celeb-A[64],AFLW[65]全数据集,LS3D-W[66]数据集(面孔在姿势,照明,表情和遮挡方面有很大的差异)VGGFace2 的子集[67](每个身份 10 个大姿势图像;9131 个身份)。高分辨率数据集采用了翻转,缩放和旋转等方法进行数据增强。为了能够从数据集中生成对应的人脸关键点图,本文采用 Opencv Dlib 库生成 HR 对应的人脸关键点。本文总共获取了 121215 张高分辨率的图片。
对于低分辨率 LR 数据集,主要有两个。首先是从 LS3D-W 数据集中随机挑选了 1000 张图像并做了预处理从其中裁剪出人脸组成数据集。第二个数据集是 LR testset,本文从 Widerface[68]创建了现实世界的 LR 数据集,它是一个非常大的且多样化的人脸数据集,其中包含受到各种降级和噪声类型的影响的人脸。总共,我们使用了超过 50000 张图像,其中 3000 张是随机选择并保存以进行测试的。
我们从 WLFW[69]的模糊子集中选取了 773 张模糊照片组成 test_blur 数据集,采用暗通道的方法对模糊核进行估计,形成模糊核的集合,并随机从集合中选取模糊核作为输入。对于人脸的关键点(Facial Landmark)的提取,本文在 HR 数据集上使用 Opencv Dlib 库生成 HR 对应的 68 个人脸的关键点图。在整个训练过程中学习率被设置为 1e – 4,公式中的 和 的权重 和 被设置为 1,0.05。模型的batch_size 的大小为 128。模型是在 PyTorch 上训练的并且优化算法是 Adam[70] ( =0, = 0.9)。
..........................
总结与展望
随着卷积神经网络和深度学习的快速发展,超分辨率的效果不断提升,也给其他任务如脸部检测,医学图像,目标检测和分割提供了帮助。但是超分辨率仍然有亟待解决的问题,因为超分辨率是从低分辨率恢复成高分辨率,这相当于从无到有恢复细节,或者利用自身 patch 的相似性,或者利用先验信息来恢复丢失的特征信息。总之,超分辨率应能够处理真实场景中的 LR 图像,提高泛化能力来应对更复杂的场景。
而针对于大多数方法只采用双三次下采样的方法获取 LR 数据集的主要问题。本文通过 GAN 构建真实数据集。首先用 KernelG AN 来生成接近真实世界的数据集,再将 LR-HR 对送入到 CRSR 模型进行训练。
本文的主要贡献如下:
(1)模糊核嵌入获取拥有复杂降质的 LR 数据
针对采用单一双三次下采样的问题,本文提出使用更真实的模糊核来构建LR-HR 数据集。本文采用暗通道的方法在真实的数据集上生成真实的模糊核并构成模糊核的集合。在模糊核集合上随机选择模糊核作为一个输入,从而生成具有复杂降质的 LR 数据集,来提高超分辨率网络的泛化能力。本文模糊核的先验信息的嵌入与之前其他研究的方法的不同之处在于将模糊核在 HR 的退化中嵌入。
(2)人脸关键点先验信息嵌入维持人脸几何结构信息
因为生成式对抗网络的具有很大的不稳定性,所以为了保证 GAN 的收敛并且保证生成的 LR 的人脸不变形,我们引入了人脸关键点来保证人脸的几何结构的完整性。
参考文献(略)