1 绪论
1.1 研究背景
最初图形处理器(Graphic Processing Unit,GPU)虽然可以独立于中央处理器(CentralProcessing Unit,CPU)进行像素缓存区的更新,但其功能依旧十分有限,只能用于纹理组合的数据计算或者像素颜色值的计算,大部分的数据计算处理还是需要依赖于 CPU。随着计算机技术的更新迭代,数据量的增加让人们对计算机的处理速度提出了更高的要求,如在卫星成像、天气预测、基因测序等领域数据规模达到了 TB 量级,显然传统的以 CPU 为主导进行数据处理的计算机无法负载如此庞大的计算需求。因此,伴随着 GPU可编程环境的出现,相比于 CPU 拥有更多算术逻辑单元(Arithmetic and Logic Unit,ALU)的 GPU 开始逐渐被各个领域应用。
与拥有复杂的逻辑控制单元的 CPU 相比,GPU 更多的是类型相同的计算单元,这让 GPU 不同于 CPU 需要利用逻辑控制单元进行逻辑判断,处理各种复杂的数据。GPU利用大量的计算单元提高计算机的处理能力和存储器带宽,实现其高吞吐量和高并发的特性(目前 NVIDIA 最新的 Ampere 架构的 A100 TESDSOR CORE GPU 集成的晶体管数量达到 542 亿,拥有 108 组 SM 单元,6912 个 CUDA 核心,核心带宽达到了 1.6TB/s,总带宽达到了 600GB/S,TDP 约为 400W[1])。也正因为 GPU 具有这些特性,让其逐渐成为了各个领域数据计算处理的关键性加速器,比如在 2020 年美国橡树岭国家实验室利用 IBM 的 Summit 超级计算机以较短的时间寻找到了当前抑制新冠疫情蔓延最有效的药物,为疫苗研发争取了宝贵的时间[2];人工智能领域利用 Tensor Core 大大提升 AI 计算的浮点性能;游戏、电影行业利用 RTX 2080 GPU 实现了视觉效果上的飞跃等。可以说,GPU 经历了四十多年的发展,正在一步步改写信息化社会的未来。
.........................
1.2 GPU 功耗国内外研究现状
GPU 的高性能通常伴随着高功耗的产生,而 GPU 的功耗来源可以被划分为静态功耗、动态功耗、短路功耗三种类型。高功耗不仅遏制了系统性能的发挥,还降低了电池的使用寿命,给处理器带来安全隐患。针对以上功耗引发的问题,本节总结了国内外功耗优化技术存在的不足,以作为本文对降耗优化技术研究的突破点。
1.2.1 GPU 功耗
GPU 因具有众多的计算核和高带宽等特性使其拥有高并发和高吞吐量的特点,在大规模并行和高性能计算中得到了广泛的应用,但是其并行处理能力的提升同时也伴随着系统功耗的急剧增加。在 2019 年 11 月发布的 TOP500 超算排名榜单中,排名前十的超级计算机通过 GPU 的高并发、高吞吐量的特性将其性能发挥到极致,但是高功耗带来的负面影响却未得到控制。在同年发布的最节能超算(Green500)排名中,“神威-太湖之光”以总功耗 15371KW,能效比 6.051GFLOPS/Watt 排在 Green500 名单中的第 35 位,而“天河二号”超算系统以总功耗 18482KW,能效比 3.325FLOPS/Watt 排在第 77 位[3]。为了维持超级计算机的高性能,研究者们正以庞大的成本与代价抑制功耗对其造成的负面影响。功耗已经成为限制处理器性能发挥的关键性因素。
GPU 的功耗来源可以被分为静态功耗、动态功耗和短路功耗三种类型[4]。静态功耗主要是晶体管漏电流引起的,当系统处于关机状态即器件全部关闭时产生的泄漏功耗和当系统处于无负载待机状态下的功耗都属于静态功耗,又称泄漏功耗。动态功耗是指当门翻转,电路节点在 0 和 1 之间跳变时,进行充放电产生的功耗。在这个跳变的过程中,PMOS 和 NMOS 会根据当前处于充电或放电状态进行导通或截断操作,同时部分能量也会被 PMOS 和 NMOS 吸收,成为系统的动态功耗。而短路功耗是指在跳变过程中,PMOS 和 NMOS 均处于导通状态而产生的功耗。它通常被归类为动态功耗的一部分,数值较小,可以忽略不计。随着处理器工艺水平的提高,其单位集成的晶体管数量与日俱增,导致其功耗密度也在不断上升,这使得处理器的设计面临着严峻的功耗挑战。
..............................
2 GPU 体系结构与 CUDA 架构
2.1 GPU 体系结构
GPU 体系结构的发展最早可以追溯到 NVIDIA 公司在 1999 年提出的第一款具有GPU 概念的 Geforce 256,它将曾经 CPU 负责的 T&L 功能整合到了 GPU 中,使得 GPU渐渐独立于 CPU。伴随着 GPU 可编程性的提高,CUDA、OpenCL[21]等架构的出现,对GPU 进行计算编程已经不是一件困难的事情,这使得 GPU 逐渐成为了当前各个领域发展不可或缺的加速器。
GPU 的广泛应用促使人们对 GPU 的性能要求逐步上升,为了满足人们对 GPU 高性能的需求,GPU 的体系结构也在不断地更新换代。NVIDA 一直致力于 GPU 体系结构的研发,从 Fermi、Maxwell、Kepler、Pascal、Volta 架构再到最新的第八代 GPU 架构——Ampere,GPU 的体系结构在每个阶段都得到了很好的提升。

图 2.1 基于 NVIDIA Ampere 架构的 GA100 总体架构图
........................2.2 CUDA 架构概述
GPU 虽然具备强大的计算能力,但是在初期阶段研究者只能通过标准图形接口才能与 GPU 进行交互,这代表着研究者在利用 GPU 执行计算之前,要考虑严格的资源和编程限制,还要了解 GPU 的底层结构运行机制,掌握复杂的计算机图形学和着色语言。如此高的学习门槛,不仅增加了研究者的学习负担,还将 GPU 的编程执行过程复杂化,这让许多研究者在进行数据分析或者模型计算时并未把 GPU 纳入考虑范围之内。但是2007 年 NVIDIA 公司提出的统一计算设备架构(Compute Unified Device Architecture,CUDA)彻底解决了这些问题,让研究者能够不再过多地考虑各种交互限制,利用类 C语言方便快速地编写 GPU 并行程序。
2.2.1 CUDA 软件层次结构
图 2.3 表示了 CUDA 软件层次结构。它主要包含了三个不同层次的接口,分别为CUDA 驱动 API、CUDA 运行时 API 和 CUDA 函数库[23]。
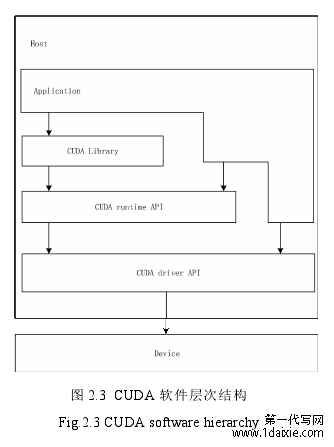
图 2.3 CUDA 软件层次结构
3 基于线程调度的功耗优化方法.....................................17
3.1 典型的线程调度算法...........................................17
3.2 基于数据依赖的线程调度及其功耗优化方法......................................18
4 基于缓存置换的功耗优化方法......................................25
4.1 典型的缓存置换算法............................................25
4.2 基于访问时间和数据块大小的缓存置换及其功耗优化方法.......................26
5 实验设计和结果分析...................................30
5.1 实验平台......................................................30
5.1.1 仿真实验平台的精准度..................................30
5.1.2 实验配置................................31
5 实验设计和结果分析
5.1 实验平台
下面首先对仿真实验平台的精准度进行了验证,并对实验的硬件配置和监控的部分数据进行简要描述。
5.1.1 仿真实验平台的精准度
为了估测并提高 GPUWattch 模拟器中功耗模型的精准度,研究者设置了一组硬件测试部件,用于测量实际功耗结果与模拟器上得出的功耗结果之间的偏差值[32]。实测采用的 GPU 架构分别为 GTX480 和 Quadro FX 5600,图 5.1 展示了在执行基准测试程序时,这两款 GPU 架构中硬件实测功耗与模拟器得出的功耗的对比情况。GTX480 架构的平均精确度为 12.6%,而 Quadro FX 5600 架构的平均精准度为 15.5%。由图可知,GTX480 架构中的模拟功耗和实际功耗差距相比较于Quadro FX 5600 架构的功耗对比差距更小,同时也与硬件实测水平相差无几。因此,利用仿真实验平台进行功耗优化研究是可行而又有效的。
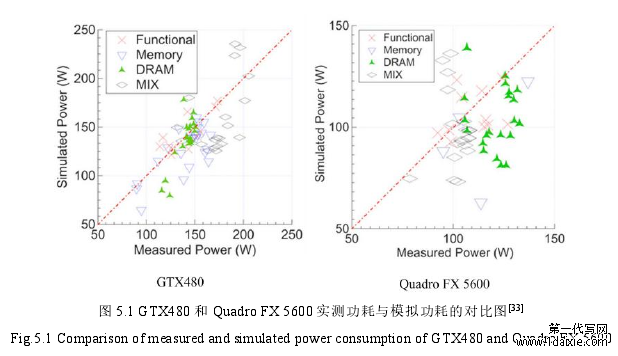
图 5.1 GTX480 和 Quadro FX 5600 实测功耗与模拟功耗的对比图
6 总结和展望
6.1 总结
相比较于 CPU 而言,拥有大量计算处理资源的 GPU 被广泛地用作具有大量数据并行任务应用程序的加速器,受到了越来越多领域的欢迎。然而,使用 GPU 加速数据处理依赖于其高带宽和高并发的特性,这通常伴随着功耗成本的提升。功耗的增加不仅会影响到处理器的性能,还会影响到芯片的散热、使用寿命以及可靠性等诸多方面,严重威胁到了 GPU 在各个领域的潜能发挥。针对功耗问题,国内外提出了许多降耗解决方案,可以归类为三种:(1)硬件级;(2)体系结构级;(3)软件级。当前,由于工艺制造水平已经难以做出突破性进展,因此硬件级方法对降耗的优化空间已经急剧缩小,而体系结构级和软件级方法得到了越来越多的关注。然而,国内外的降耗技术虽对功耗产生了一定的优化效果,但是依旧存在复杂性高、实现成本高、伸展性低等缺陷,并且对占据功耗较大部分的访存功耗涉及甚少。因此,本文从线程调度和缓存置换两个角度出发,分别提出了 DDTS 方法和 TBC 方法。
为了减少处于不同 SM 中的线程对共享的相同数据进行跨 SM 访问操作,DDTS 方法根据线程与数据块之间的依赖关系,将共享相同数据块的线程分配到同一个 SM 中,以降低数据传输功耗。但是,由于存在一个线程会访问多个数据块的情况,为了进一步降低数据传输功耗,需要对线程组之间进行交集判断,如果存在交集则进行将线程组进行合并,如果不存在交集则不做打算。这种判断交集合并的做法虽然进一步降低了数据传输功耗,但是由于没有考虑合并后数据块的大小与缓存空间的比较情况,所以可能会导致合并后的数据块大于或远小于缓存空间的情况,因此针对此类情况,将大于缓存空间的合并后的数据块拆分,同时也对其对应的线程组不再进行合并,并先后分配到 SM中执行。将远小于缓存空间的合并后的数据块进行多次合并直到接近于缓存空间大小,同时也将合并的数据块对应的线程组进行合并,并将它们一起分配到 SM 中执行。通过以上方式,在合理分配线程的情况下,尽可能地降低跨 SM 带来的数据传输功耗。经过实验验证,我们的 DDTS 方法相比于共享感知数据管理方法在 L1 缓存未命中率方面下降了约 6.3%,在 DRAM 数据传输量方面下降了约 7%,在能耗方面下降了约 10%。
参考文献(略)