第 1 章 绪论
1.1 研究背景和意义
1.1.1 研究背景
大数据的不断发展推动者数据库和存储技术的不断前进。近年来随着互联网用户的急速增长,互联网产生的数据呈爆炸式增长。数据量的增加意味着数据的提取和分析难度更大,同时数据的存储和管理也更加的困难。传统的数据库、文件系统和数据仓库面临着越来越大的挑战。大量的数据存储、分析平台和工具被开发出来,目前比较常用的大数据框架系统是 Apache Spark[1],其核心是使用的弹性抽象分布式数据集 RDD[2]。
随着硬件技术尤其是存储设备的不断发展,针对文件系统的研究进入了一个新层面。Anna[3]、OctopusF S[4]等项目的研究成果表明针对不同类型、速度的硬件设备而区分设计的分层次文件系统是一种可行的存储方案。它同时兼顾了成本和响应速度等多方面的需求。大量针对不同硬件而设计的文件系统被设计并开发出来,并应用在大数据分析和人工智能领域的方方面面。另一方面,类似于Trilogy[5]、BEAG(Balanced Distribution for Each Age Group) [6]之类的项目开展,很多新的对不同节点间的数据调整放置策略被研发出来,使得分布式集群下的节点负载程度有效得到了降低。
虽然在现有的针对大数据的存储、读取和负载优化的相关研究已经比较丰富,但是针对高维且数据分布稀疏的数据进行有效存储和读取方面的研究仍然较少。传统的文件系统或数据仓库无法利用高维数据的特性进行更加优化的存储和查询。因此,面对特殊的高维稀疏数据,如何进行高效的存储进行查询是一个必须解决的问题。
1.1.2 研究意义
高效的数据存储和查询不仅需要高性能的计算机支持,同时也需要高效的算法策略来进行数据的有效存储和排序。然而,在实际情况下每个方面都有着不同的难题。在对高维稀疏数据进行有效查询的前提是数据如何进行高效的存储和排列。无规律的数据存储会导致数据在磁盘进行查找时浪费大量的时间,尤其在数据维度高时这个问题会更加明显。其次,数据的特殊性会导致建立索引更加的困难。最后,随着数据量的不断增大,分布式节点之间必然会有数据分布不均匀的情况。在信息爆炸的 5G 时代,互联网每时每刻都在产生着海量的数据,数据量的增大必然会导致分布式节点间查询时间的变慢。因此,数据的存储量暴增是一个无法回避的问题。数据存储量的增加还可能会导致不同存储节点所存储的数据量的差别逐渐增大,因此如何在分布式存储节点之间进行动态的数据调节以保证数据的高效查询同样是非常必要的研究方向。
..............................
1.2 相关技术国内外研究现状
1.2.1 对角存储的研究现状
数据管理策略也可以称为数据放置策略,自上世纪开始它就是一个比较热门的研究内容。自互联网出现以来,互联网所产生的数据就在爆炸式增长。数据的查询速度和响应速度更是数据库系统、分布式文件的重要性能指标,因此如何高效管理这些数据始终是一个绕不开的话题。当前的数据管理策略在分布式文件系统和数据分析系统中有着非常重要的价值,因此相关研究人员经常能够提出新的方法应用在现有的分布式文件系统用以改进或优化系统的性能。现有的数据放置策略大致可以分为基于 hash 的方法和基于非 hash 的方法两大类,下面针对不同的类别分别进行介绍。
基于哈希的数据放置策略研究中,David K[7]等人基于 consistent hashing 提出了一个特别的缓存协议,使得用户在不必知道数据的全局分布情况下也能够将数据均匀的分布在不同的计算机中。在文献[8]中,Scott A.Brandt 等人同时结合了目录子树分区和 hash 的优点,提出了一种名为 Lazy Hybrid 的元数据管理策略,在一定程度上解决了这两种技术存在的瓶颈问题。在文献[9]中,Weijia L 等人提出了动态哈希(Dynamic Hashing)的方法进行元数据管理。同时引入了 Relative LoAd Balancing 策略在工作负载动态变动时进行元数据分布的调整,从而提高了系统的适应性和性能。Cassabdra[10]同样使用一致性哈希环来进行数据的分区,但是它通过分析节点间的负载信息来进行轻负载和重负载节点的互换来保持数据的分区一致,从而达到均衡负载的目的。John L[11]提出了一种快速、内存占用小的跳跃一致性哈希算法进行数据放置,改良了 bucket 数量变化情况下的表现,使得此方法更适用于数据存储。然而一致性哈希环在异构环境中效率并不理想,因此 Jiang Z等人在文献[12]中提出了一种新的 attributed consistent hashing 方法。它通过一种属性间自适应的数据放置策略在一定程度上克服了现有一致性哈希算法的不足。
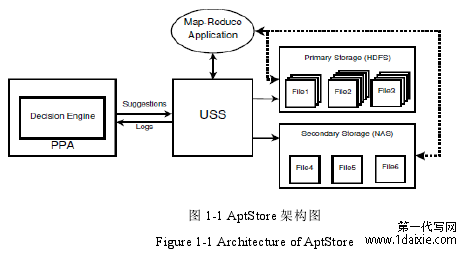
图 1-1 AptStore 架构图
第 2 章 相关知识引入
2.1 对角存储方法介绍
20 世纪 90 年代开始,计算机系统得到了快速的发展。数据库系统为了满足更快的查询和写入速度,必须提高磁盘 I/O 的速度。为了提高磁盘 I/O 的速度,并行计算系统逐渐兴起。而对角存储的概念就是在这个时期提出。对角存储的目的是为了解决数据库系统中 CPU 和磁盘 I/O 速度不匹配问题。J.L 等人在此文章中不仅提出了 CMD 的概念,同时也证明了其合理性。
所谓对角存储,其实是一种数据划分存储的方法。假设某数据库系统存储的数据有 d 个不同的属性,即该数据有 d 个维度。对于该输入数据的每个维度,我们用 Di 来代表第 i 维属性(1≤i≤d)。那么该输入数据的其中一条记录可以表示为一个 d 维度的元组(r , , r , … , ), ∈ D 。由于对于输入数据来说我们需要进行对角存储的数据划分,因此我们假设该输入数据都是有界数据,即对于数据的每一个属性的取值都有明确的上下界。因此对于所有的 d 个维度属性上的数据,我们都可以将每个属性上的每个值都映射到某个具体的维度空间。假设输入数据的每个维度我们都映射到了[0,1)区间,那么我们就可以用一个单元空间 S=[0,1)d来表示所有属性的映射。
假设并行系统中总共有 M 个磁盘,并且划分参数为 t。那么 S 上的每一个维度都会划分为 tM 个不同的间隔,每个间隔都包含一个固定维度的数据内容。每个 间 隔 的 长 度 都 为 1/tM, 最 终 所 有 划 分 出 来 的 数 据 间 隔 就 是 :[0, 1/tM), [1/tM,2/tM),[2/tM,3/tM),……,[(tM-1)/tM,1)。为了方便表示,每个间隔我们分别从0 到 tM 进行编号。最终 S 总共划分为了(tM)n个不同的区域,并且每个区域都是 n个区域间隔的笛卡尔积。
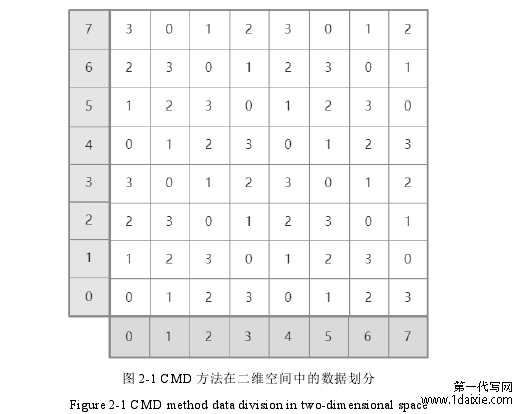
图 2-1 CMD 方法在二维空间中的数据划分
..........................
2.2 B-/B+树算法概述及应用
B 树是一种特殊状态的二叉树。普通的二叉树每个节点只有一个条目或信息,该节点的指针指向下一个孩子节点;而 B 树的每个非叶子节点都可以拥有多个子节点,每个子节点都包含信息并有指针指向孩子节点。普通的二叉树没有自平衡结构,其节点只会向下延展。二叉树的左右分支数量、节点数量可能相差很大,因此不同数据的查找速度可能相差很大。B+树元素自底向上插入,这与二叉树恰好相反。B 树是一种自平衡的数据结构。在 B 树的左右节点层数相差过大时会自动的进行动态调节,使其整棵树的结构始终保持在一个动态的平衡状态。
尽管 B 树的每个非叶子节点都包含大量的子节点信息使得整体树的高度可以维持在一个较低的水平(三到四层),使得每次数据的查找都可以将查询的节点次数控制在个位数以内;但是 B 树非叶子节点存储信息却会导致过量的内存开销。当数据量过大时,B 树将会占据大量的内存空间。因此 B+树的出现成为了必然。B+树的整体结构和 B 树类似,只是 B+树的非叶子节点仅仅是索引而不再存储具体的数据信息。所有的数据信息都存储在 B+树的叶子节点且所有的叶子节点用链表的方式串联在一起以方便于顺序查找。B+树的这一改变将所有的数据查询操作的次数都固定下来,同时非叶子节点不存储具体的数据信息的特点将大大降低内存开销。叶子节点的这种特性同时方便进行序列化等操作来进一步降低内存开销。
由于 B+树的种种优点,他被广泛的应用在关系型或非关系型数据库中。如典型的 MyS QL、Oracle 和 PostgreS QL 等数据库,NTFS、Btrfs 和 Ext 等文件系统。 B 树的结构示意图如图 2-2 所示,B+树的结构示意图如图 2-3 所示:
B-树从发明至今已有五十多年的历史。从 B-树发明至今已经被广泛的应用在数据库、操作系统和文件系统中。B+树是 B-树的改进索引算法,成功解决了 B-树索引不连续和内存占用过大的问题。B-树/B+树是一种平衡、高效且可用进行文件和数据库索引的改进二叉树。为了加速 B-/B+树的索引速度和效率,在这几十年的时间内前人做了很多的改进和尝试。通过增量式碎片整理来减少日志工作量的方法改进 B-树来适用于写最优方案成为可能[40]。
..............................
第 3 章 局部对角存储的方法 .................................... 15
3.1 引言 ........................................ 15
3.2 预备知识 ............................ 15
第 4 章 基因 LRU 的数据不平衡条件下的 Rebalance 方法 .................................. 33
4.1 引言 ......................................... 33
4.2 预备知识 .............................33
结论与展望 .............................. 42
第 4 章 基因 LRU 的数据不平衡条件下的 Rebalance 方法
4.1 引言
网格文件在分布式文件系统中的数据划分会导致数据在不同节点的分布不均匀的情况发生;这种数据分布不均匀的情况在参与划分的数据分布没有规律或分布不符合预期时都会非常明显。为了保证分布式存储在各个节点性能接近的情况下查询速度的大致相等,针对分布不均匀的节点进行数据的动态调整因此变得尤其重要。为了系统的整体的稳定性,本章提出了一种基于 LRU 的节点间数据Rebalance 方法。利用内存置换算法创新性的进行不同存储节点之间的网格文件数据块的动态调节。通过优先进行被访问不活跃的数据块的调整,最大程度上保证系统的整体性能不被影响。
本节在阐述新的 Rebalance 方法之前,先进行一些理论知识的介绍以方便于文章的阅读和理解。分别介绍了 LRU 置换算法和 LRFU 置换算法。虽然这些页面置换算法是被发明用来进行内存页面的置换,但是网格数据的存储方式在一定意义上和分页存储非常相似,内存置换算法同样也能被用来进行网格数据块的置换,并且这种巧妙的替换方法应用在文件数据块的替换同样能达到不错的效果。
.............................
结论与展望
本文基于对角存储方式这个前提条件,通过对大数据存储、对角存储算法进行相应的研究,从对角存储的数据划分和 B+树的索引这两个角度出发,深入的研究了网格文件划分的优缺点,提出了一种基于 CMD 的系数数据划分查询方法。针对 CMD 方法数据进行数据划分导致划分的网格文件指数级增长导致难以管理的问题,利用先验的知识选取数据集中分布规律的部分属性进行 CMD 的网格划分,防止此方法产生大量的数据块。同时针对未参与数据划分的多为属性,提出了一种利用 Bitmap 的存储思想对每条数据的未参与数据划分的属性进行索引;而索引基于 B+树算法,B+树的节点内计划采用改进的三点插值法来进行内部数据的查找。实验证明利用局部对角存储进行范围查询的方法可以获得非常好的范围查询的性能。
利用 CMD 方法进行网格文件的划分必然会导致节点间数据分布的不均衡问题。本人被内存置换算法所启发,同时对比了文件置换和内存置换的差异,利用LRU 算法在内存置换时的简单高效性,提出了一种基于 LRU 算法的数据分布不均匀状态下的再平衡方法。实验证明,数据在经过此番调整后可以在一定程度上加快范围查询的速度,是一种可行的数据再平衡方法。
当前情况下,由于网络数据的爆发式增长,单纯的分布式架构越来越难满足大数据量的存储要求。利用硬件性能的差异进行分层次的分布式存储方法变得非常流行。此种方法根据不同硬件在存储性能和价格上的差异,将不同的硬件较为充分的利用起来。因此基于分层次的分布式存储成为本人的下一个研究方向。包括但不限于如何将基于 CMD 的数据划分方法利用在分层次存储解决方案上,以及如何更有效的平衡分布式存储节点间的查询数据量等内容。
参考文献(略)