第一章 绪论
第一节 研究背景和意义
2018 年中国图书零售市场销售码洋总量达到 894 亿元,同比增长 11.3%,从 2014 年以来,连续 5 年保持两位数的高增长态势。其中,线上销售渠道的销售规模继续保持高速增长,线上网络书店销售规模从 2017 年的 459 亿元上升到2018 年的 573 亿元;而线下实体书店则再次出现负增长,码洋规模从 2017 年的344 亿元下滑到 2018 年的 321 亿元,同比下滑 6.7%。随着我国图书行业的快速发展,对于图书市场的预测逐渐成为出版社进行决策的重要手段。尤其对于细分领域的销售码洋的预测对于出版社是否要在这一领域继续投入新品的决策有重大意义,某一细分市场销售码洋的成长性对于出版社投入的图书品种能否获得畅销有着很大的作用。所以,能够准确预测某一细分市场的销售码洋对于图书市场有着极大的参考价值。
传统的图书产业链模式,出版社与读者的信息链条是割裂的[1],导致出版社无法获取有效的销售数据、出版机构不了解市场等情况,所以会导致出版社盲目扩大生产品种、下游经销商粗放采购、大批量退货和库存积压等情况。加之图书行业的品种较多、整体信息化水平低、经营模式原始等一系列问题。虽然近些年图书市场整体市场规模稳步增长,但相对落后的供应链已经成为限制一些市场持续发展的持续因素。图书市场的出版商、发行商、零售商亟待通过信息化改造与整合,实现销售信息的互通和行业的整合优化,提高整体经营效率。随着近些年互联网技术的发展,对零售业已经产生了颠覆性影响[2],很多线下的业务开始向线上转移,图书零售业也不例外。
随着网上书店的快速发展和人们生活方式的转变,更多的消费者倾向于在网上购买图书。网上书店的快速发展对于图书销售信息采集以及消费者的洞察有着重要意义。爬虫技术的发展使得对网上海量的图书销售信息的采集成为可能。实体书店由于网络书店的冲击,大部分连锁书店都开始信息化转型,改变了之前粗放的进货模式,所有大型实体书店进货、销售均通过 ERP 系统进行对接,使得具体的销售数据的获取成为可能,完整的图书销售数据的获取对于精准预测图书市场有着重要意义。
........................
第二节 数据来源
本文的销售码洋数据来源于开卷每月发布的图书销售数据,目前开卷数据涵盖了超过 150 万条标准书目,是国内图书行业最大的数据提供商。开卷数据分为实体店和网店监控数据,实体店监控数据为全国 1410 个县级以上城市的 3435家书店门店的销售数据,而网店数据是通过对天猫和京东的销售数据进行汇总的数据。本文中的日语市场销售码洋数据为开卷的四级分类中的日语图书的销售码洋数据,该数据可以极大程度上反映日语市场的涨跌情况。
本文的搜索因子数据来源于百度指数,百度指数是以海量的网民搜索行为数据为基础,是目前我国最重要的互联网数据统计分析平台。某个关键词在百度搜索规模的变化,能够反映网民一段时间内对于某个关键词的关注程度,进而能够反映整体市场的一些变量的变化情况。本文中的百度指数原始数据为以日为单位的搜索规模,通过以月为单位进行取平均值处理,获得以月为维度的百度搜索指数。
本文的研究思路如下:本文首先通过已有的关于日语图书市场相关影响指标的文献,获取有关提取关键词的方法。然后,基于所提取的关键词获取其百度指数,并对百度指数的时间维度进行按月归一化处理。通过使用主成分分析的方法进行关键词的降维处理,根据其显著性保留影响较大的因子,并消除每一类关键词之间存在的多重共线性。最后,本文利用经验模态分解(EMD)的数据处理方法将日语市场销售码洋分解为不同尺度的 IMF 进一步合成不同频率的时间序列,然后通过 ARIMA 模型以及多元回归模型对不同频率的数据分别进行预测。除此之外,本文还将该模型应用于于日语市场销售码洋的拐点预测,证明其有效
............................
第二章 文献综述
第一节 网络搜索数据的应用信息技术的高速发展带来了更加便利的信息获取路径[4],颠覆了传统消费者获取信息的模式,最为突出的就是消费者很多购买的决策都基于对于网络搜索数据的利用,并且搜索引擎逐步成为用户搜索信息最为方便快捷的工具。用户在享受互联网时代搜索信息的便利性的同时,也将自己的搜索行为数据留存在了搜索引擎中,大量的搜索记录信息汇聚在一起,包含了很多互联网用户在现实生活当中的真实行为意图,搜索引擎采集的数据与传统的问卷式的数据采集方法更能反映调研对象的真实意图,更是互联网用户群体的社会性、经济性规律和发展趋势的反映。
随着互联网的全面普及,近些年对网络搜索数据相关的经济、社会、文化、研究与预测研究已成为一个学术热点,该领域研究起步较晚,大多数研究开始于在 2000 年之后,近些年在国内外取得了一定的研究成果,但是目前成体系的研究尚还不够健全。在国外,有关网络搜索数据的研究方面已经涉及了经济、社会以及健康领域之中[5, 6]。在经济领域中,搜索数据可用于消费以及失业率的预测。Wu L, Brynjolfsson E[10]等利用谷歌搜索数据与房屋销售价格和销量之间的关系进行拟合构建模型,通过谷歌搜索数据对房屋售价和销量走势进行预测;Konstantin A.[11]等预测美国私人消费率,以谷歌趋势数据为基础数据,通过比较包括密歇根大学消费者情绪指数及信心指数、金融变量谷歌趋势数据等模型的预测精准度,得出结果是传统的预测模型精度远低于基于谷歌搜索 Query 数据的预测模型;Nikolaos Askitas K F Z[12]等通过 Google 中工作相关的搜索指数预测美国失业率,通过构造 500 多个预测模型并进行预测效果对比,发现基于工作搜索指数的模型预测效果远优于传统模型的预测效果,另外,以美国 51 个州失业率为样本检验预测模型的鲁棒性,其预测效果高于构费城联邦储备银行的预测效果。网络搜索数据在社会健康领域中也有了广泛的应用,在预测公众关注力及流感等疾病方面也取得了不错的成果。Jeremy Ginsberg[13]等通过研究 Google与流感相关的搜索记录发现谷歌搜索数据与流感的看病人数存在极强相关性,而且所选取的大部分关键词的搜索量和流感看病人数有很强的相关性,通过分析医院流感就诊量和流感相关关键词搜索量之间的相关关系,Ginsberg 等建立了以 Google 搜索量为基础的预测模型,该模型取得良好的预测效果,可以提前 10-14 天预测出流感的爆发趋势;Kulkarni Gauri[14]等通过研究谷歌搜索关键词与新产品销量之间的关系,通过选取搜索关键词,构建了新产品的搜索因子模型,与传统的模型相比,搜索数据更加具有及时性,有利于产品供货商及时调整生产数量,与传统模型相比,预测更加精准。
...............................
第二节 经验模态分解(EMD)算法
经验模态分解算法(Empirical Mode Decomposition)是 Huang[20]于 20 世纪末期年提出的,该算法基于信号局部特征时间尺度,从原信号中提取固有模态函数(Intrinsic Mode Function)。经验模态分解(EMD)方法被认为是近些年来以傅立叶变换为数学基础的线性和稳态频谱分析领域科学研究的一个重大突破,该方法是依据数据自身的不同的频率特征来对信号进行分解,该方法优点是不需要假定任何基函数。这与建立在谐波基函数和小波基函数上的傅里叶分解与小波分解方法具有显著的差别。所以,EMD 分解方法用于处理非平稳、非线性的时序数据的分析方面具有很大优势,具有很高的信噪比。EMD 分解方法的应用最早起源于大气波动的研究中[21],后面逐步拓展运用到自然科学领域,例如:生物医学工程、土木工程等[22];也广泛应用在对电子信号源的分解中[23, 24],后面推广至经济、社会科学领域,但在社会科学领域还很少应用[21, 25, 26]。
国外在经验模态分解上的应用主要有以下几方面:Zhang[27]等人将 EMD 运用到油价的预测中发现,EMD 算法可以很好地处理非平稳、非线性序列,是提取数据序列趋势的较好方法。ZhaoLi,Rui Li[8]等人通过对傅里叶变换、小波变化和经验模态分解进行比较,发现 EMD 能很好地识别出地层界面从而挖掘相关的地质信息。Chencheng Guo[28]等人将 EMD 算法运用于检测供水管道泄漏,研究发现利用 EMD 算法可以消除信号中的噪声,从而提高泄漏定位误差。国外主要是将 EMD 运用于信号处理及大宗商品的价格预测中,大宗商品价格以及信号的数据一般是非平稳的时间序列数据,可见国外多将经验模态分解算法(EMD)运用于非平稳时间序列的预测。
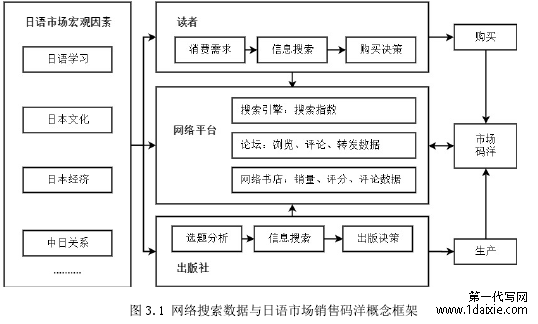
图 3.1 网络搜索数据与日语市场销售码洋概念框架
第三章 网络搜索数据采集及搜索因子构建 .................11
第一节 理论基础...............11
第二节 关键词选取与数据预处理....................12
第四章 预测模型的构建及评估 ...........................25
第一节 理论基础.............25
一、经验模态分解(EMD)理论 ....................................... 25
第五章 总结...........................................60
第一节 结论.................60
第二节 创新点和局限性..................16
第四章 预测模型的构建及评估
第一节 理论基础
一、经验模态分解理论
经验模态分解(EMD)理论是 Huang 于 20 世纪末提出的一种旨在处理非线性、非平稳时间序列的方法,EMD(EmpiricalModeDecomposition)经验模态分解方法被认为是近些年来以傅立叶变换为数学基础的线性和稳态频谱分析领域科学研究的一个重大突破,该方法是依据数据自身的不同的频率特征来对信号进行分解,该方法优点是不需要假定任何基函数。这与建立在谐波基函数和小波基函数上的傅里叶分解与小波分解方法具有显著的差别。它基于系统中很多重要的参数,如各种频率的相关能量的直接提取,将复杂的信号分解成若干数量的内在本征模态函数 IMF(Intrinsic Mode Function)和一个残差。
EMD 算法需满足三个假设条件:
1. 数据大于或等于一个的最大值和最小值;2. 极值点间的时间尺度决定数据的局部特性的唯一确定性;3. 如果数据没有极值点并且同时存在拐点,必须要求可以对数据进行微分处理,进而获取极值点,并且再通过积分获得分解结果[40]。
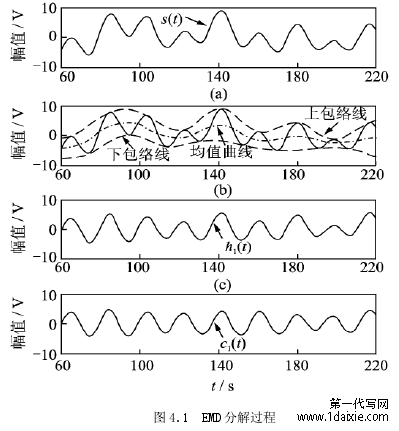
图 4.1 EMD 分解过程
第五章 总结
第一节 结论
及时有效的对市场进行预测,一直都是各个行业关注的热点,能够对市场动向进行及时、准确的预测,对于企业有着很强的参考意义。图书行业对于市场的研究较为传统,主要依赖于机构报告、市场调研等研究数据,这些数据来源相对滞后,并且不具有前瞻性。而其他一些对于图书销售的预测研究应用的模型较为传统,并不能很好抵抗市场其他因素的影响作用。而本文通过对于理论模型的创新应用,对于图书行业日语细分市场的预测的精度有了很大程度的提高。
随着互联网的普及,人们对于信息的获取越来越依赖于网络搜索数据,使得消费者行为的数据在互联网变得有迹可循。近年来,网络搜索数据的研究价值也逐渐引起了学者的关注。本文通过 EMD 算法首先将日语图书市场销售码洋的时间序列数据进行分解,分解为高频、中频、低频和趋势项四个变量,并分别尝试与搜索因子数据进行回归或者直接应用其他模型进行预测,经过实验,获得显著的、预测精度最高的模型,在预测准确性上由于其他传统预测模型。
本文的主要结论如下:
1、证明了对日语图书市场销售的相关关键词的选取是有效的,通过对这些关键词进行主成分分析构建的搜索因子对日语图书市场销售码洋时间序列数据进行预测是可行的,并且在预测的准确率上优于传统的时间序列模型。
2、证明了使用当期网络搜索数据在对图书细分市场的模型的预测中是有效的。读者的需求很大程度上会反映在网络搜索数据上,尤其像图书类产品的销售转化周期较短,即消费者从搜索信息到界定购买的时间差较短,所以使用当期的网络搜索数据对图书细分市场的销售情况进行预测是有效的。
参考文献(略)