第 1 章 绪论
1.1 研究背景
自 2006 年起,加拿大多伦多大学教授、机器学习领域的著名学者 Geoffery Hinton等在国际学术刊物《Science》上发表了文章[1]提出深度学习的思想以来,提出了两个观点:(1)含多个隐藏层的人工神经网络具有十分强大的特征学习能力,通过训练模型所提取的特征对原始输入数据相比更具有抽象表达本质的能力,从而更加有利于特征的可视化或者分类问题;(2)可以用无监督学习算法来实现“逐层的初始化”,实现对输入信号的数据进行分级表达的目的。随后深度学习在学术界和工业界快速升温,之后随着计算机技术在人工智能领域中深度学习[1][2][3][4]的快速发展,逐渐在计算机视觉领域的应用中得到了快速发展,深度学习的方法[3]逐渐和计算机视觉领域中的目标检测[5][6]得到了融合。不同的行业已经把关于目标检测的计算机视觉技术应用其中,应用前景[7][8][9][10]十分广阔,通过计算机视觉技术可以有效减少人力资源的损耗并在一些领域可以加速工业化进程,具有十分重要的应用价值[11]。因此,目标检测技术近些年来成为了工业界和学术界关注的重点方向,也是计算机视觉的主要应用领域。
随着计算机运算能力的不断的加速和互联网共享资源不断积累利用计算机图像处理技术对目标进行检测的研究越来越受到重视。在交通方面,被广泛用到公交公路中,如行人、车辆、车道线、标示牌、红绿灯等检测;监控系统中的人脸识别、异常行为识别等;医学中的图像肿瘤检测、其他病理识别;在农业中用于果实检测;在军事用于一些无人机检测等,都体现了基于深度学习的目标检测技术相对于传统的目标检测的优势[5]。传统的目标检测技术由于在实际应用场景中往往会因为复杂场景的需求而导致无法进行实时检测等情况的发生。当基于深度学习的目标检测技[5][6]术在面对以上的问题时大放异彩,使得基于深度学习的目标检测技术成为了众多课题研究中的一个的热点。但是,现有的基于深度学习的目标检测仍旧面临一些问题。其中,多类别识别准确率率低以及小目标识别检测的精度低等问题是该研究领域不得不面临的一个主要现状。在针对基于深度学习中的目标检测技术在实际应用中,尤其是在复杂场景中关于中小的目标所面临的检测精度低等关键问题的研究背景下,如何能够有效的改善现有算法并提高检测精度具有十分重要的意义。
.........................
1.2 国内外研究现状
基于深度学习的目标检测相较于传统的方法而言具有更明显的优势,有更好的鲁棒性和准确性。对于传统的目标检测算法而言,其算法主要包括六个关键步骤,其中包括预处理、窗口滑动、特征提取、特征选择、特征分类和后处理[5]。早期的传统的目标检测的特征信息提取本质上是一种基于手工设计的特征,如基于图像梯度直方图的局部特征(SIFT)[12]、全局特征(HOG)[13]等方法,然后再利用支持向量机(SVM)[14]、自适应提升(Adaboost)[15]等分类器对提取的信息特征进行分类识别。概括的来讲,传统的目检测主要采用了特征提取+分类的模式。如,2001 年 Viola 和 Jones 等提出将 Haar特征和 Adaboost 分类器结合的图像识别的方法[16]。但是,这些算法有着共同的缺陷,例如针对不同的识别问题,提取到的特征的好坏对系统的性能有着直接的影响,必须设计出适应性更好的特征,以满足系统的性能,一般都是针对某一特定问题进行识别。无法应用于不同的场景,虽然检测效果不错,但是无法适用于多场景复杂条件下的目标检测,并且关于数据的规模不大,泛化能力差,无法解决实际需求中的精准识别问题[17]。
这几年深度学习的发展在目标检测中出现了变革式的创新,众多的基于卷积神经网络的检测模型在图像识别领域中不断的提出,基于深度学习的目标检测成为逐渐的计算机视觉领域中的热门的方向。一方面研究学者们构建了丰富的图像数据库,如 PASCALVOC 数据集[18]、MS COCO 数据集[19]等;另一方面对构建的神经网络不断地提出新的观点以及思路,如 2013 年 Girshick 提出的基于区域卷积神经网络(R-CNN)[20]正式的打开了基于深度学习的目标检测大门,该算法模型引入了基于选择性搜索算法的区域候选框机制,将目标检测在 PASCAL VOC 2007 数据集上的检测精度从 29.2%提高到了 66%,2015 年的 Faster Rcnn 网络[21],引入了感兴趣区域机制,但其仍是基于选择性搜索的策略,使得网络的运行时间大部分消耗在了关于区域候选框的机制上,RCNN 和 FasterRcnn 等算法,主要是在基于区域候选的思想,首先对检测区域提取候选区域,然后为后续特征提取和分类准备。2016 年 Redmon 提出的 Yolo 目标检测算法[22]实现了端到端[23][24][25]的检测,真正的实现了及时响应的需求,但是它的准确率没有 Faster-Rcnn 高;同时在网络性能方面。
.......................
第 2 章 关于深度学习目标检测的相关理论基础
2.1 深度学习概述
人工智能(Artificial intelligence)是计算科学领域的分支之一,是指通过试图了解智能的本质,并使得通过人制造出的机器具备智能的表现。它是使得机器具备智能表现所用到的模拟、延伸和扩展人的智能的理论、方法以及技术应用的一个综合的技术学科。而人工智能领域一个分支则是机器学习(Machine Learning),它是 AI 领域的核心。简而言之,机器学习的主要研究对象就是可以使得计算机从数据中解析并且从中学习,然后实现对现实世界中的事件做出预测或者决定的算法。机器学习就是从以往的历史数据中找出规律,然后将该规律用于对未来未知的场景的预测。而深度学习[1][2][3][4](DeepLearning)又是实现机器学习中的一个分支,近年来成为机器学习领域取得重大突破和热点之一。突破它解决的主要问题就是可以自动地将简单的特征[38]组合成更加复杂的特征,并使用这些组合特征来解决问题。并且,它除了可以学习特征和任务之间的关联之外,还可以自动地从简单特征中提取更加复杂的特征。机器学习和深度学习的流程如图2-1 所示:
........................
2.2 神经网络基础理论
2.2.1 神经元基本模型
一般地,一个简单的神经网络由一个输入层、若干个隐藏层以及一个输出层组成,但是无论该神经网络由哪层结构组成,其都会有多个神经元[39]组成。每个神经元的基本结构是相同的。一个神经元会接受来自不同权值 w 的信号 x,然后求和,再进行非线性计算,得到该神经元的输出。非线性操作模拟了生物神经元的信号传播,通常是由一个非线性激活函数来模拟的,通常神经元有一个阈值,当信号足够强大的时候能够激活神经元然后将信号传递给下一个神经元。
2.2.2 前向传播算法
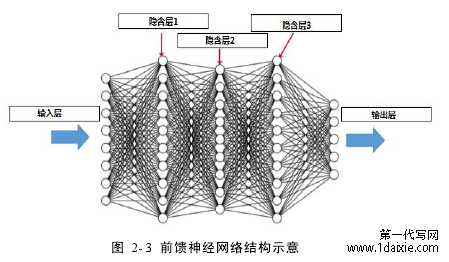
通过一组神经元可以组成一个隐藏层或者输入层,然后即可将这些层组合在一起可连接成一个神经网络[39][40]。在神经网络中有许多不同的结构,但是最常见的神经网络结构就如图 2-3 示意图所示,即前馈神经网络结构。在该结构中,除了第一层的输入层和最后一层的输出层以外,其他层都是隐藏层。
........................
第 3 章 基于 SSD 模型的目标检测的研究与改进..........................19
3.1 对 SSD 网络模型的分析................................19
3.1.1 对选用的 VGG 主干网络分析..............................19
3.1.2 对 SSD 中各个卷积层的分析.................................20
第 4 章 基于目标区域特征放大的改进 SSD 模型...........................32
4.1 对改进的 SSD 网络模型进一步分析.......................32
4.2 对于 SSD 模型的网络模型的设计.......................33
4.3 浅层卷积层输出的目标区域放大机制............................34
第 5 章 总结及展望...............................43
第 4 章 基于目标区域特征放大的改进 SSD 模型
4.1 对改进的 SSD 网络模型进一步分析
本文在第三章对 SSD 网络模型进行分析过后,首先针对小目标检测方面提出了在浅层卷积层单元中通过联系上下文的信息来检测中小目标的改进思路。因为在浅层特征图中,较小的检测目标会因为后面连续不断地卷积层的卷积操作和池化操作而可能使得更多的细节丢失,换句话说,卷积核和池化核的存在造成了卷积层之间的连接都是局部连接,这也是卷积神经网络无法对输入的原图进行全局感知的根本原因。因此,卷积网络中的每个神经元无法对输入的图像进行全局的感知是造成语义丰富程度不一样的根本原因。
沿着上文提到的思路针对浅层的特征检测层,本文运用反卷积处理的方法对低层中的卷积检测层提取到的特征图进行可视化分析得出有利于分析小目标的卷积层。因此,在对浅层的卷积特征图的中输出的特征图进行研究时,运用反卷积操作提升特征图的分辨率,使得原本特征图的含有的细节信息更加丰富。
在研究过程中表明,从第三章中给出的相应的计算公式表明一个卷积神经网络在不同的特征层的语义程度是和感受野之间存在某种联系的[58][59][60],即感受野的大小决定了每层语义的丰富程度。而感受野其实就是输出的特征图在某节点响应的输入图像的一个区域。语义越丰富,对应的感受野就越大,相反细节也就越少[61]。
.......................
第 5 章 总结及展望
本文针对现有的目标检测领域中暴露的关键问题,即小目标识别检测精度不高的问题,从两个角度出发:第一,两次特征融合都是为了增强卷积检测层输出的特征图对信息的表达;第二,对模型输出的目标建议区域进行特征放大,增强目标区域对细节得表达。全文两次改进思路从本质上来讲都是为了使得特征图上的细节信息得以较好的保留,从而在卷积检测层中获得一个较好的检测效果。而今后,随着更为复杂的应用场景的出现,多卷积层多尺度的检测的网络会在实际生活中得到更为广泛的应用。因此,本研究的意义在于为复杂场景下面向中小目标的检测提供了一个可行的研究思路。
本文的主要贡献在于:
(1)对目标检测领域的研究现状进行了现状分析,分析了不同的研究学者在基于深度学习的目标检测方面对于提升小目标检测能力的研究思路。
(2)本文分析了不同的卷积神经网络模型的基本原理,并根据现有实际应用场景中所暴露的关键问题,选取了更为有效的基于端到端的思想的多卷积多尺度预测的 SSD网络模型。
(3)针对小目标检测精度不高的问题,从原理上分析了其存在的原因。并且从卷积检测层输出特征图的着手进行了网络结构的优化以及上下文信息的融合。
(4)在针对预测框中小目标特征信息丢失的问题时,本文采用了对目标建议区域映射放大的方法来增强小目标的特征信息的显示效果。
(5)分别针对两次叠加的改进思路,设计了新的网络结构以及方法,采用了相同的测试数据集和训练数据集,进行了实验效果的验证,最后证实了该方法的可行性。
参考文献(略)