第 1 章 绪论
1.1 研究背景和意义
当今人工智能,特别是深度学习技术本身具有强大的特征提取能力,因此这一技术被目前的很多需求或场景广泛使用,例如语音交互、行为识别以及嵌入式终端等。回顾卷积神经网络 CNN(Convolution Neural Network)的发展历程,最早在 1998 年,由 Le Cun 提出 Le Net 这一卷积神经网络模型,是卷积神经网络的开山之作,该模型约有 1M 的参数量;2013 年,由 Krizhevsky 等提出的AlexNet 深度神经网络模型,其参数量达到了 200M;之后 VGG-16 网络模型的参数量更是达到了 500M,接近 6100 万个参数,虽然这些模型通过巨大的参数量保证了自身在分类和检测任务上优越的性能,但是这些模型的参数中也存在着巨大的冗余,冗余的参数不仅不会对模型的预测精度有任何贡献,相反还会使得深度网络模型很难部署到嵌入式等设备,因为大多数的嵌入式设备本身内存较小并且电池的电量也很有限。
1.1 研究背景和意义
当今人工智能,特别是深度学习技术本身具有强大的特征提取能力,因此这一技术被目前的很多需求或场景广泛使用,例如语音交互、行为识别以及嵌入式终端等。回顾卷积神经网络 CNN(Convolution Neural Network)的发展历程,最早在 1998 年,由 Le Cun 提出 Le Net 这一卷积神经网络模型,是卷积神经网络的开山之作,该模型约有 1M 的参数量;2013 年,由 Krizhevsky 等提出的AlexNet 深度神经网络模型,其参数量达到了 200M;之后 VGG-16 网络模型的参数量更是达到了 500M,接近 6100 万个参数,虽然这些模型通过巨大的参数量保证了自身在分类和检测任务上优越的性能,但是这些模型的参数中也存在着巨大的冗余,冗余的参数不仅不会对模型的预测精度有任何贡献,相反还会使得深度网络模型很难部署到嵌入式等设备,因为大多数的嵌入式设备本身内存较小并且电池的电量也很有限。
近年来随着手机、平板电脑以及 VR 等移动或嵌入式设备广泛流行,伴随着人工智能特别是深度学习技术的快速发展,越来越多的智能软件被应用到移动端设备上,尤其像苹果 Apple 和脸书 FaceBook 这样以手机应用为主的公司,都会通过各自不同的应用商店将智能软件提供给用户下载或者更新。伴随着人们对于智能软件以及人工智能(Artificial Intelligence)技术提出越来越高的要求,如语音识别软件能够准确快速的分析不同语言的输入,手机面部解锁技术在极短时间内进行活体识别检测等,这些需求使得深度学习技术面临这样几种问题,首先软件本身使用的深度学习模型大小就已经在 100M 以上,如果软件不支持增量下载,人们就将无法通过移动网络在应用商店中进行下载,我们经常会在应用商店中见到这样的提示,“除非应用程序支持增量下载,否则你只有连接无线局域网才能下载”,另外,如果开发者希望上架自己的软件,想要通过应用商店的审核也不是一件易事。一些经典的网络模型如 AlexNet 网络模型,其大小在 200MB 以上,而 VGG-16 模型更是达到了 500MB 以上,像自然语言处理 NLP(Natural Language Processing)中使用的深度学习模型大小一般在 1G以上。通常情况下,这些巨大的网络模型是无法直接在片内进行存储访问的,因此会消耗很多动态存取过程,例如 DRAM(Dynamic Random Access Memory)。其次,这样的存储访问控制形式也极大地影响设备能量的消耗。Han[1]等在一个45nm 工艺的互补金属氧化物半导体 CMOS(Complementary Metal Oxide Semicondictor)中,32 位的整型加法操作接近消耗 0.1pJ,一个 32 位浮点类型乘法过程接近消耗 3.7pJ,与此同时,32 位的静态存取过程消耗大约 5pJ 的能量,例如 SRAM(Static Random Access Memory), 一个 32 位 DRAM 存储接近消耗 640pJ。举个例子,在 40HZ 下运行接近 10 亿个连接的神经网络,单在 DRAM存储过程中需要的能量就达到(40HZ)*(1G)(640pJ)=25.6w。显然这样的深度神经网络模型是无法直接在手机这样的具有电量约束的嵌入式设备上运行的。
..........................
1.2 国内外研究现状
针对模型压缩,目前所有的压缩方式主要可以分为两大类,一类是针对前端的压缩方法,另一种是针对后端的压缩方法。前端压缩方法主要包括知识蒸馏、紧凑的模型设计以及基于滤波器级别的裁剪;后端压缩方法主要包括低秩近似、不加限制的裁剪和参数量化及二值化。针对后端压缩的方式,其压缩方式往往是不可逆的,后端压缩为了追求极致的压缩率,往往需要开发配套的运行库和硬件设备。因此目前更多的模型压缩方式主要是基于前端压缩方式中的基于滤波器级别的剪枝策略。Huang[2]等将这种裁剪方式又分为两种,一种是基于结构化的裁剪方式,另一种是无结构化即采用随机裁剪的方式。下面我们主要介绍一下这两种模型裁剪策略,并且本文的模型裁剪方法与基于滤波器级别的裁剪有一定的相似之处。
1.2.1 基于结构化裁剪策略
基于结构化的裁剪主要针对于深度神经网络模型的结构而言,这种裁剪方式首先人为的定义一些条件,然后通过相应的计算裁剪掉一些低于某个阈值的卷积核、连接或特征图中某个通道并最终达到模型压缩的目的。
Li[3]等提出了一种基于轻量级的裁剪方式,该方法对卷积核中所有的权重的绝对值求和作为该卷积核的一个评价标准,然后将一层中绝对值之和较低的卷积核进行裁剪,同时作者考虑到深度神经网络模型的每一层对于裁剪的敏感程度不同,该方法针对对于裁剪较为敏感的层使用较小的裁剪粒度或者直接跳过不裁剪,针对不敏感的层设置较大的裁剪粒度,从而可以做到在有效地降低模型复杂度的同时不会对模型的性能造成很大的损失。Hu[4]等发现在很多的深度神经网络中,有绝大部分的神经元在经过激活函数激活操作之后,其结果接近于 0,而接近于 0 的参数在网络中的意义较小,因为作者认为这些接近于 0的参数对网络的表达能力贡献较小,需要把这些参数进行裁剪。为了对这些激活值接近于 0 的参数进行统计,论文的作者提出一种新型的方法名为APoZ(Average Percentage Zeros),通过该评价方法,能够对网络中一些价值较小的参数进行数量统计,从而优化网络的结构以达到压缩的目的。实验的结果发现,在 VGG-16 这一深度网络模型中大约有 631 个 filter 的 APoZ 超过了 90%,也就说明了模型中的参数存在着巨大的冗余。Luo[5]等提出可以对神经网络中的卷积核进行熵运算,裁剪的策略就是将所有卷积核的熵值进行排序,并且通过设定相应的阈值以裁剪网络中的冗余参数,优化网络结构。
...........................
第 2 章 模型压缩与图像分类网络
2.1 模型压缩的基本概念
传统的卷积神经网络凭借本身巨大的特征提取能力,被广泛的应用到各种场景中。但是很多传统的深度神经网络被证明本身含有大量的冗余参数,这些冗余的参数很大程度的影响了模型的收敛速度,同时由于嵌入式等设备本身CPU 计算能力,内存限制以及电池电能的限制,使得这些深度学习模型很难应用到这些移动端的设备上。
目前针对模型压缩的两个主流思路是,一种思路是设计一些轻量化的模型[20] [50],如 MobileNet、SqueezeNet 等,模型本身的参数量较小,可以针对不同的精度需求进行裁剪优化。另外一种思路是保持传统的深度神经网络模型结构不变,通过一定的方法进行结构优化[1][12],从而减少模型的参数量和浮点运算量我们经常提到的网络模型压缩主要是指第二种思路,在不改变网络结构的前提下,使密集网络模型变得稀疏。目前针对前端模型压缩方法还可以分为以下几类,包括:更加精细化的模型设计,模型的剪枝以及卷积核的稀疏化。除此之外在一些新的领域如量化学习,矩阵分解以及迁移学习等针对模型压缩方法也有很多的研究。在保证深度神经网络预测精度的同时,通过对深度神经模型进行压缩,减少模型本身的冗余参数,使得其能够轻松地部署到手机等嵌入式设备上。
............................
1.2 国内外研究现状
针对模型压缩,目前所有的压缩方式主要可以分为两大类,一类是针对前端的压缩方法,另一种是针对后端的压缩方法。前端压缩方法主要包括知识蒸馏、紧凑的模型设计以及基于滤波器级别的裁剪;后端压缩方法主要包括低秩近似、不加限制的裁剪和参数量化及二值化。针对后端压缩的方式,其压缩方式往往是不可逆的,后端压缩为了追求极致的压缩率,往往需要开发配套的运行库和硬件设备。因此目前更多的模型压缩方式主要是基于前端压缩方式中的基于滤波器级别的剪枝策略。Huang[2]等将这种裁剪方式又分为两种,一种是基于结构化的裁剪方式,另一种是无结构化即采用随机裁剪的方式。下面我们主要介绍一下这两种模型裁剪策略,并且本文的模型裁剪方法与基于滤波器级别的裁剪有一定的相似之处。
1.2.1 基于结构化裁剪策略
基于结构化的裁剪主要针对于深度神经网络模型的结构而言,这种裁剪方式首先人为的定义一些条件,然后通过相应的计算裁剪掉一些低于某个阈值的卷积核、连接或特征图中某个通道并最终达到模型压缩的目的。
Li[3]等提出了一种基于轻量级的裁剪方式,该方法对卷积核中所有的权重的绝对值求和作为该卷积核的一个评价标准,然后将一层中绝对值之和较低的卷积核进行裁剪,同时作者考虑到深度神经网络模型的每一层对于裁剪的敏感程度不同,该方法针对对于裁剪较为敏感的层使用较小的裁剪粒度或者直接跳过不裁剪,针对不敏感的层设置较大的裁剪粒度,从而可以做到在有效地降低模型复杂度的同时不会对模型的性能造成很大的损失。Hu[4]等发现在很多的深度神经网络中,有绝大部分的神经元在经过激活函数激活操作之后,其结果接近于 0,而接近于 0 的参数在网络中的意义较小,因为作者认为这些接近于 0的参数对网络的表达能力贡献较小,需要把这些参数进行裁剪。为了对这些激活值接近于 0 的参数进行统计,论文的作者提出一种新型的方法名为APoZ(Average Percentage Zeros),通过该评价方法,能够对网络中一些价值较小的参数进行数量统计,从而优化网络的结构以达到压缩的目的。实验的结果发现,在 VGG-16 这一深度网络模型中大约有 631 个 filter 的 APoZ 超过了 90%,也就说明了模型中的参数存在着巨大的冗余。Luo[5]等提出可以对神经网络中的卷积核进行熵运算,裁剪的策略就是将所有卷积核的熵值进行排序,并且通过设定相应的阈值以裁剪网络中的冗余参数,优化网络结构。
...........................
第 2 章 模型压缩与图像分类网络
2.1 模型压缩的基本概念
传统的卷积神经网络凭借本身巨大的特征提取能力,被广泛的应用到各种场景中。但是很多传统的深度神经网络被证明本身含有大量的冗余参数,这些冗余的参数很大程度的影响了模型的收敛速度,同时由于嵌入式等设备本身CPU 计算能力,内存限制以及电池电能的限制,使得这些深度学习模型很难应用到这些移动端的设备上。
目前针对模型压缩的两个主流思路是,一种思路是设计一些轻量化的模型[20] [50],如 MobileNet、SqueezeNet 等,模型本身的参数量较小,可以针对不同的精度需求进行裁剪优化。另外一种思路是保持传统的深度神经网络模型结构不变,通过一定的方法进行结构优化[1][12],从而减少模型的参数量和浮点运算量我们经常提到的网络模型压缩主要是指第二种思路,在不改变网络结构的前提下,使密集网络模型变得稀疏。目前针对前端模型压缩方法还可以分为以下几类,包括:更加精细化的模型设计,模型的剪枝以及卷积核的稀疏化。除此之外在一些新的领域如量化学习,矩阵分解以及迁移学习等针对模型压缩方法也有很多的研究。在保证深度神经网络预测精度的同时,通过对深度神经模型进行压缩,减少模型本身的冗余参数,使得其能够轻松地部署到手机等嵌入式设备上。
............................
2.2 模型压缩的基本方法
2.2.1 更加精细化的模型设计
目前,大部分网络模型是基于模块化的设计,这些网络极力追求网络模型本身的深度以及宽度,原因是要想使模型的预测精度能够有更高程度的提升,就必须增加网络模型的深度和宽度。这类模型设计导致网络模型本身在深度和宽度上都非常大,从而使得这样一些基于模块化设计的网络本身含有大量冗余的参数。
为了解决传统深度神经网络在部署到移动端时遇到的模型存储空间占用大以及计算复杂两个方面的问题,近几年一些轻量化的模型如 MobileNet[20] ,SqueezeNet[50]等被提出,其使用更加精巧、高效的模型设计方法,能够很大程度上减小模型本身在深度以及宽度上的设计尺寸,轻量化的模型设计在大幅度降低冗余参数的同时也尽可能的保证了模型本身的预测精度。此类精细化模型的卷积操作大都由很小的卷积核组成,如 1*1 和 1*3,首先在运算量上比非精细化模型下降很多,同时模型的预测精度也达到了很好的效果。
2.2.1 更加精细化的模型设计
目前,大部分网络模型是基于模块化的设计,这些网络极力追求网络模型本身的深度以及宽度,原因是要想使模型的预测精度能够有更高程度的提升,就必须增加网络模型的深度和宽度。这类模型设计导致网络模型本身在深度和宽度上都非常大,从而使得这样一些基于模块化设计的网络本身含有大量冗余的参数。
为了解决传统深度神经网络在部署到移动端时遇到的模型存储空间占用大以及计算复杂两个方面的问题,近几年一些轻量化的模型如 MobileNet[20] ,SqueezeNet[50]等被提出,其使用更加精巧、高效的模型设计方法,能够很大程度上减小模型本身在深度以及宽度上的设计尺寸,轻量化的模型设计在大幅度降低冗余参数的同时也尽可能的保证了模型本身的预测精度。此类精细化模型的卷积操作大都由很小的卷积核组成,如 1*1 和 1*3,首先在运算量上比非精细化模型下降很多,同时模型的预测精度也达到了很好的效果。
SqueezeNet,该网络不同于传统的深度神经网络的卷积方式,[50]提出一种新的概念叫做 file module,该结构分为两部分,包括 squeeze 层和 expand 层。其中 squeeze 层包含大量的 1*1 卷积,将卷积之后的特征图(feature map)输送到expand 层中进行 1*1 和 3*3 的卷积,最后将所有的特征图进行合并。MobileNets,采用一种深度可分离的网络卷积方式代替传统的卷积方式,深度可分离卷积主要分为 depthwise 卷积以及 pointwise 卷积,depthwise 对于不同的通道使用不同的卷积核,而 pointwise 卷积完全使用 1*1 的卷积方式,从而降低模型本身的参数量和计算量以达到能够部署在移动端等嵌入式设备上的效果。ShuffleNet[51], 这种网络解决了组卷积方式带来的信息流通不畅的问题,很大程度上减少了模型本身的参数量。
.............................
3.1 相关符号介绍 ............................................. 21
3.2 主动逐步网络模型裁剪 ..............21
第 4 章 实验与分析 .............................................. 27
4.1 裁剪 AlexNet 模型在 ImageNet 数据集上的表现 .................... 28
4.2 裁剪 VGG-16 模型在 CIFAR10 数据集上的表现 ...................... 31
第 5 章 总结与展望 ...................................... 38
5.1 总结 .......................................... 38
5.2 展望 ............................... 38
第 4 章 实验与分析
4.1 裁剪 AlexNet 模型在 ImageNet 数据集上的表现
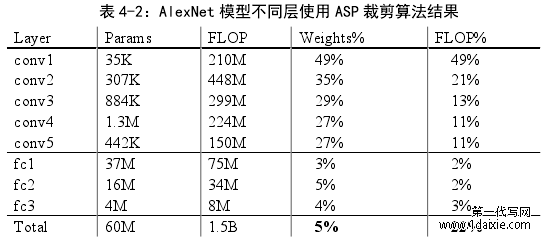
我们首先将我们的方法应用于 AlexNet。 我们使用 AlexNet Caffe 模型作为参考模型,并使用 ImageNet 数据集训练该模型[3]。该模型需要在训练过程中了解大约 60M 参数,其中包括 5 个卷积层和 3 个完全连接的层。由于考虑到模型包含很多层,因此会导致一些问题,如消失梯度或爆炸梯度。因此为了避免相应的问题出现,我们需要将模型的卷积层和全连接层分开裁剪,首先保证模型的全连接层参数,对卷积层参数进行裁剪,同理,保证模型的卷积层参数,然后对全连接层参数进行裁剪。
...........................
第 5 章 总结与展望
5.1 总结
在本文中,我们提出了一种适用于移动端设备的复杂卷积神经网络模型压缩方法。我们使用对数函数 Log 来控制修剪过程,为了防止错误的修剪,我们提出了一种参数恢复策略,并有效地计算了模型中参数的有效性。与一些需要设置太多超参数的当前模型修剪方法不同,我们的方法仅使用 3 个超参数就能实现模型最终的稀疏度。同时,修剪和微调可以自动同步地进行。实验结果证明了我们的方法的有效性。在 MobileNet,AlexNet,VGG-16 和 ZFNet 模型上,压缩率分别达到 5.6x,19.4x,20.0x 和 15.2x,并且模型的预测精度几乎没有降低,因此复杂的模型可以灵活移植到移动平台。与此同时,我们的方法只需要20 次迭代就能达到最终效果。将来,我们会将我们的方法应用于更多领域,并测试其对某些复杂模型的影响。
5.1 总结
在本文中,我们提出了一种适用于移动端设备的复杂卷积神经网络模型压缩方法。我们使用对数函数 Log 来控制修剪过程,为了防止错误的修剪,我们提出了一种参数恢复策略,并有效地计算了模型中参数的有效性。与一些需要设置太多超参数的当前模型修剪方法不同,我们的方法仅使用 3 个超参数就能实现模型最终的稀疏度。同时,修剪和微调可以自动同步地进行。实验结果证明了我们的方法的有效性。在 MobileNet,AlexNet,VGG-16 和 ZFNet 模型上,压缩率分别达到 5.6x,19.4x,20.0x 和 15.2x,并且模型的预测精度几乎没有降低,因此复杂的模型可以灵活移植到移动平台。与此同时,我们的方法只需要20 次迭代就能达到最终效果。将来,我们会将我们的方法应用于更多领域,并测试其对某些复杂模型的影响。
本文对深度卷积模型压缩作了深入的研究。为了解决深度神经网络由于本身参数量和计算量均较大而无法无损迁移到移动端的问题,文中对于出现的问题进行了深入的分析,并相应的提出了解决算法。虽然相比较于对比实验,我们的方法有很大的进步,但是目前仍然存在一些改进的空间,可以从以下方面继续进行研究。
1、在修剪的策略上本文主要考虑的是修剪卷积核,另外我们接下来可以考虑修剪网络中的通道,或者两种方式一起使用。
2、本文中的稀疏度上限是经验值,针对不同的网络结构可能需要设置不同的上限值,以后可以采用更加有效的裁剪策略,提升算法的泛化能力。
参考文献(略)
1、在修剪的策略上本文主要考虑的是修剪卷积核,另外我们接下来可以考虑修剪网络中的通道,或者两种方式一起使用。
2、本文中的稀疏度上限是经验值,针对不同的网络结构可能需要设置不同的上限值,以后可以采用更加有效的裁剪策略,提升算法的泛化能力。
参考文献(略)