第一章 绪论
1.1 研究背景及意义
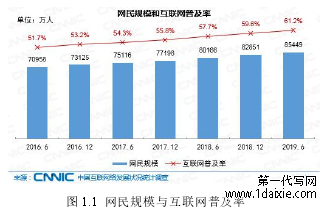
对于人们日常生活而言,互联网早已是不可或缺的组成部分,中国的互联网也有着极为快速的发展趋势,本世纪互联网相关数据增幅稳居世界前列[1],据 CNNIC(中国互联网络信息中心)于 2019 年 08 月 30 日发布的《2019 年第 44 次中国互联网络发展状况统计报告》统计,如图 1.1 所示,截至 2019 年 6 月,我国网民规模达 8.54 亿,较 2018 年底增长 2598 万,较2016 年底提升 1 亿 4491 万,互联网普及率达 61.2%,较 2018 年底提升 1.6 个百分点,较 2016年底提升 9.5 个百分点。
.....................
1.2 研究现状
针对 JavaScript 恶意代码之检测技术,目前国内外相关研究正处积极发展之阶段。
Angluin[15]将最有利于机器学习效能的样本选出,加以人工标记后用以分类模型训练,该方法受到网络安全领域的广泛关注。
Almgren[16]等于入侵系统中引入主动学习,获取到了较好的检测性能。
李洋等[17]将主动学习与 K 最近邻算法相结合用于入侵检测,减少了样本标记量和算法开销,GU 等[18]研究了主动学习应用于入侵检测的现状,指出了一些不足和需要改进的方向。
文献[19]中采用 ESVM(Editing Supporting Vecto r Machines)方法提高泛化能力,但是需要重复使用 SVM 训练进行迭代的样本剪裁,做法十分的复杂。
Likarish[20]等人提取代码中的关键字作为特征,应用机器学习算法进行分类来进行脚本检测,该方法只考虑了脚本特征中关键字的不同分布,并没有考虑一些可执行的方法与函数特征,导致特征类型过于单一,特征维度太低。
Al-Taharwa 等人[21]通过分析 JavaScript 脚本语义特征,建立抽象语法树来进行分类检测,但并没有考虑到 JavaScript 脚本中混淆代码的特性。因此难以准确检测。
Fraiwan 等人[22]在脚本的频繁特征,URL 特征,函数特征和执行特征的基础上构建相应的分类模型,亦是缺乏对混淆特征的考虑。
.........................
第二章 相关背景知识介绍
2.1 WEB 安全基础理论
2.1.1 WEB 应用概念
WEB 应用指的是 WEB 应用程序[30],是一种应对服务器或 WEB 的动态拓展,从面向对象划分,WEB 应用可以分为两种类型,分别为面向服务与面向表现。面向服务的 WEB 应用构建了服务端点,而面向表现的 WEB 应用程序会产出大量包含动态内容与多种标记语言的交互式 WEB 页面处理响应相关用户请求。通俗地讲,WEB 应用可认为是由多个 JSP 页面,HTML 文件,Servlet 以及图像文件组成的动态应用,基于上述功能,WEB 应用可以为互联网用户提供完整的网络服务。
2.1.2 WEB 应用安全
随着社交网络,WEB2.0,微博,ins 等新型互联网应用的飞速发展,基于 WEB 环境之下的相关应用也是层出不穷,日新月异,使用越来越广泛。当然,针对 WEB 应用安全的威胁也随之而来,并日渐突显,攻击者往往会针对 WEB 应用的程序漏洞进行特定攻击,通过获得相关服务的控制权从而盗取用户相关隐私信息,借此进行恶意攻击与非法活动或危害用户的财产安全。目前较为常见得 WEB 应用安全攻击主要包含 Phishing 钓鱼网站,Plug-ins andSript-Enabled 攻击,Drive-By Downloads 网页木马,Clickjacking 点击劫持攻击以及 SQL 注入攻击等[31]。
(1)Phishing 钓鱼网站
网络钓鱼是欺诈性攻击[32]。 通常从事合法业务(例如学校,网络服务提供商,银行等)通过电子邮件窃取用户的个人信息。平时这些电子邮件会将用户定向到伪造的钓鱼网站或将其发布私人信息(例如密码,信用卡或其他用户帐户更改)获得的私人信息用于身份盗用[33]。
.......................
2.2 JavaScript 语言概述
JavaScript 语言是面向对象的编程语言。JavaScript 起初主要用于网站的表单验证,随着网络的发展与 JavaScript 语言的不断改进完善,如今已经成为了 Web 应用最主要的组哼部分之一,是所有 WEB 页不可或缺的主要功能,功能性也大卫丰富,能够完成更多更复杂的计算机交互任务,并不再局限于对于表单验证。也正是因此,所以功能日渐强大,与用户的网络行为联系越来越紧密频繁,从而导致了基于 JavaScript 代码之恶意攻击日渐增加,发展迅速,花样多变,难以防范。固本章节特总结与简述了 JavaScript 代码相关语言特性,近年新增语言标准,主流攻击技术。并由此展开后续的特征提取相关工作。
2.2.1 JavaScript 语言特性
依据现有最新的 JavaScript 语言标准可知,JavaScript 主要由三部分得以组成,分别是浏览器对象模型(Bower Object Model,BOM)与文档对象模型(Document Object Model,DOM)以及 EMAScript[46],如图 2.6 所示:

...........................
第三章 TF-NIDF 算法特征提取...............................19
3.1 传统 JavaScript 特征提取不足..............................19
3.2 增加特征提取的数量...............................19
第四章 基于 MMV 算法的脚本过滤模块...............................32
4.1 问题分析.............................. 32
4.2 V-detecctor 算法及其不足..........................32
第五章 ASVM 分类算法............................40
5.1 常见分类算法及对比..........................40
5.1.1 朴素贝叶斯分类算法...............................40
5.1.2 神经网络..............................41
第六章 JavaScript 恶意脚本检测系统实现
6.1 原型系统结构
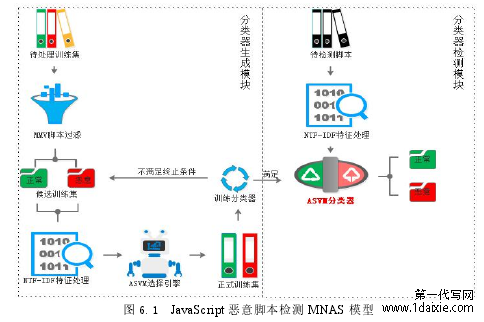
基于前面章节的研究,本文实现了从脚本过滤到特征提取到分类算法的全面优化,各个子模块综合形成了 JavaScript 恶意脚本 MNAS(MMV-detector+TF-NIDF+ASVM)检测系统。该系统主要主要依据第三章,第四章以及第五章的内容设计。系统中实现了脚本抓取的功能,该功能是依据第三章中实现的 catchJS 工具。通过提交 URL 链接实现 JavaScript 脚本抓取。系统中的特征提取功能是根据第三章的基于 TF-NIDF 加权算法实现的特征处理。在得到具体的样本之后输出处理后的特征向量。系统中实现了拟正常脚本的过滤功能,该功能是依据第四章中提出的基于否定选择的 MMV-detector 算法实现的通过成熟检测器过滤非自体。系统中的分类器训练模块是根据处理后的特征向量基于第五章中提出的ASVM分类算法进行训练器生成。在满足达到终止条件之后得到最终的 SVM 分类模型。系统中的脚本检测模块是将进行特征处理之后的待测脚本进行检测分类,并得到最终的分类值。具体的 MNAS 系统结构如图 6.1 所示;
........................
第七章 总结与展望
7.1 总结
网络技术的提升与丰富使得越来越多的网站开始以 Web 应用的形式提供服务,从而导致基于 Web 的应用呈现倍数级的增长。而 JavaScript 作为一种具有完备功能的语言,被广泛地应用于 Web 应用的前端开发之中。虽然为用户带来了诸多便利和良好的交互体验,但与此同时也给 Web 用户终端带来了不少威胁与风险。针对恶意 JavaScript 代码的传统静态检测通常是对样本进行分类标记后,提取特征向量训练生成分类器来对新的未知样本进行检测分类。然而实际成果却不尽人意。存在特征提取科学性与泛化性缺失,样本标记存在误差,分类算法训练代价过大等问题。为了得到具备更好检测性能的 JavaScript 恶意代码检测系统,本文的工作和创新点如下:
针对以上问题。本文从特征提取与脚本过滤以及分类算法优化多个方面开展开展相关课题研究,对 JavaScript 恶意代码检测中还未解决诸多问题进行深入探讨,以下是本文的创新点以及取得的成果总结:
(1)TF-NIDF 加权算法
本文结合最新的 ECMAScript2019 标准与对今年主流 JavaScript 攻击技术的研究,从四个方面增加了共计 68 个脚本特征,提高了特征提取泛化性。并将文本分类思想应用于 JavaScript脚本恶意检测,再对传统的 TF-IDF 加权算法进行针对性改进得到 TF-NIDF 加权算法带来更加具备科学性与泛化性的加权。间接有效的提高了 JavaScript 恶意代码分类模型检测性能。
(2)MMV-detecto 脚本过滤算法
本文重点关注了训练集的噪声优化,利用对 V-detector 算法进行针对性改进后的基于否定选择的 MMV-detector 脚本过滤算法,对抓取到的 JavaScript 脚本集进行降噪过滤,将包含插件与广告等非正常脚本与正常脚本区分开来,保证了样本标记时的精确度。降低训练集噪声,减少标记误差,从源头提高 JavaScript 恶意代码分类模型性能。
参考文献(略)