第一章 绪论
1.1 研究背景及意义
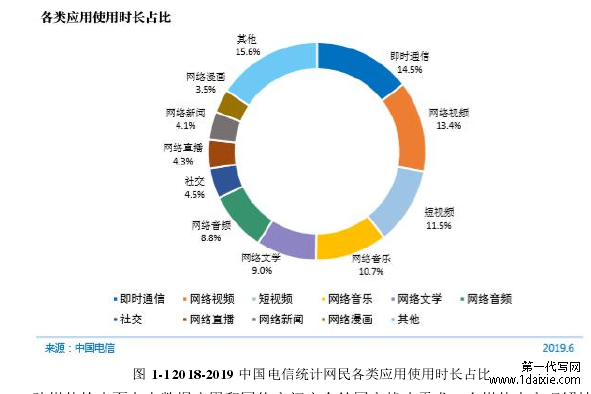
近几年来,随着科技的进步和社会的发展,信息的各种表现形式越来越多样化,多媒体数据也逐渐从原来的单一文本数据扩展到图片、语音、视频、动态图形、3D 模型等多种形式的媒体数据。不同类型的媒体数据可以从不同的角度表达相同的信息。例如,图片或视频通常与文本一起显示在网页上,用于描述同一对象或新闻事件。而随着互联网在大众生活中的普及和深入,人们不仅是网上的浏览者,也作为创造者,不断推动着互联网内容的进步和更新。据 2019 年 8 月 CNNIC 发布的第 44 次《报告》统计,截止至 2019 年 6 月,我国网民数量已达 8.54 亿,互联网已覆盖 61.2%的国人。网民当中,在网络上使用过视频的用户达到 7.59 亿,占网民整体数量的 88.8%。多模态的媒体平台已经是跨了文本、图像、视频、音频、游戏、电子商务等多个领域的网络平台,数据规模也在以指数级的增速逐年增加。作为国内最强大的数据中心之一,腾讯数据中心已经存储了 1000PB 数据,其数据规模相当于 1 万 5 千个世界最大的图书馆(美国国会图书馆)的藏书量,并以每天 500PB的速度增加。腾讯每天需要处理海量的数据,用户每天利用腾讯旗下的应用发送到网络的图像数量达到 10 亿幅,视频、音乐、漫画等应用的日浏览量达 20 亿次,春节当日转账流水超过 25 亿笔。图 1-1 为截止到 2019 年 6 月中国电信发布的网络中各类应用使用时长占比,可以看出网络生活在人们的生活中占据了大量的时间。
1.1 研究背景及意义
近几年来,随着科技的进步和社会的发展,信息的各种表现形式越来越多样化,多媒体数据也逐渐从原来的单一文本数据扩展到图片、语音、视频、动态图形、3D 模型等多种形式的媒体数据。不同类型的媒体数据可以从不同的角度表达相同的信息。例如,图片或视频通常与文本一起显示在网页上,用于描述同一对象或新闻事件。而随着互联网在大众生活中的普及和深入,人们不仅是网上的浏览者,也作为创造者,不断推动着互联网内容的进步和更新。据 2019 年 8 月 CNNIC 发布的第 44 次《报告》统计,截止至 2019 年 6 月,我国网民数量已达 8.54 亿,互联网已覆盖 61.2%的国人。网民当中,在网络上使用过视频的用户达到 7.59 亿,占网民整体数量的 88.8%。多模态的媒体平台已经是跨了文本、图像、视频、音频、游戏、电子商务等多个领域的网络平台,数据规模也在以指数级的增速逐年增加。作为国内最强大的数据中心之一,腾讯数据中心已经存储了 1000PB 数据,其数据规模相当于 1 万 5 千个世界最大的图书馆(美国国会图书馆)的藏书量,并以每天 500PB的速度增加。腾讯每天需要处理海量的数据,用户每天利用腾讯旗下的应用发送到网络的图像数量达到 10 亿幅,视频、音乐、漫画等应用的日浏览量达 20 亿次,春节当日转账流水超过 25 亿笔。图 1-1 为截止到 2019 年 6 月中国电信发布的网络中各类应用使用时长占比,可以看出网络生活在人们的生活中占据了大量的时间。
............................
1.2 国内外研究情况
国内外相当多的科研机构都有从事跨媒体检索的相关研究,国内相关方面的研究机构主要包括清华大学软件学院多媒体情报组、北京大学计算机科学技术研究所、中国科学院西安光电精密机械研究所、电子科技大学未来媒体研究中心、浙江大学人工智能研究所、厦门大学媒体分析与计算实验室、南京大学计算机软件新技术国家重点实验室等。在这当中,庄越挺教授团队从多种来源和多种模态类型的媒体信息出发,对于跨模态数据的相关性、统一性和底层特征特性学习做了深入的挖掘。北京大学彭宇新教授团队构建了第一个包含 5 种媒体类型(文本,图像,视频,音频,3D 模型)的新的跨媒体数据集 XMedia[1]。中科院光电所李学龙团队在基于哈希的检索方面做了深入的研究。
国内外相当多的科研机构都有从事跨媒体检索的相关研究,国内相关方面的研究机构主要包括清华大学软件学院多媒体情报组、北京大学计算机科学技术研究所、中国科学院西安光电精密机械研究所、电子科技大学未来媒体研究中心、浙江大学人工智能研究所、厦门大学媒体分析与计算实验室、南京大学计算机软件新技术国家重点实验室等。在这当中,庄越挺教授团队从多种来源和多种模态类型的媒体信息出发,对于跨模态数据的相关性、统一性和底层特征特性学习做了深入的挖掘。北京大学彭宇新教授团队构建了第一个包含 5 种媒体类型(文本,图像,视频,音频,3D 模型)的新的跨媒体数据集 XMedia[1]。中科院光电所李学龙团队在基于哈希的检索方面做了深入的研究。
国外方面,主要的研究机构包括美国圣地亚哥大学视觉计算机实验室,微软亚洲研究院(MSRA),伊利若亚大学香槟分校斯维特拉娜·拉泽尼克(Svetlana Lazebnik)团队,乔治亚理工大学,谷歌(Google),悉尼科技大学杨易团队和加州大学 SVCL 实验室等。其中 SVCL 专门针对本领域构建的 Wikipedia[2]数据集,有力的推动了本领域的发展。
期刊和会议方面,不少国际顶级期刊和会议也鼓励跨媒体检索领域相关文章的发表。国际顶级期刊包括 IEEE 多媒体学报(IEEE Transactions on Multimedia,简称 TMM)、模式识别(Pattern Recognition,简称 PR)、IEEE 模式分析与机器智能事务处理(Transactions on Pattern Analysis and Machine Intelligence,简称 TPAMI)、IEEE 图像处理学报(Transactions on Image Processing,简称 TIP)、国际计算机视觉杂志(International Journal of Computer Vision,简称 IJCV)等。国际顶级国际会议有 ACM 多媒体会议(ACM Multimedia,简称MM)、IEEE 国际计算机视觉会议(IEEE International Conference on Computer Vision,简称ICCV)、神经信息处理系统会议(Neural Information Processing Systems,简称 NIPS)、欧洲计算机视觉会议(European Conference on Computer Vision,简称 ECCV)、IEEE 计算机视觉与模式识别会议(IEEE Conference on Computer Vision and Pattern Recognition,简称CVPR)、国际机器学习会议(International Conference on Machine Learning,简称 ICML)等。
期刊和会议方面,不少国际顶级期刊和会议也鼓励跨媒体检索领域相关文章的发表。国际顶级期刊包括 IEEE 多媒体学报(IEEE Transactions on Multimedia,简称 TMM)、模式识别(Pattern Recognition,简称 PR)、IEEE 模式分析与机器智能事务处理(Transactions on Pattern Analysis and Machine Intelligence,简称 TPAMI)、IEEE 图像处理学报(Transactions on Image Processing,简称 TIP)、国际计算机视觉杂志(International Journal of Computer Vision,简称 IJCV)等。国际顶级国际会议有 ACM 多媒体会议(ACM Multimedia,简称MM)、IEEE 国际计算机视觉会议(IEEE International Conference on Computer Vision,简称ICCV)、神经信息处理系统会议(Neural Information Processing Systems,简称 NIPS)、欧洲计算机视觉会议(European Conference on Computer Vision,简称 ECCV)、IEEE 计算机视觉与模式识别会议(IEEE Conference on Computer Vision and Pattern Recognition,简称CVPR)、国际机器学习会议(International Conference on Machine Learning,简称 ICML)等。
.......................
第二章 跨媒体检索相关概述
 .......................
.......................
第二章 跨媒体检索相关概述
2.1 跨媒体检索的基本概念与挑战
跨媒体数据也叫跨模态数据,这类数据源跨越数据类型,来自不同时间和空间,从不同的方面描述同一个具象。譬如,如图 2-1 所示,世界乒乓球锦标赛中,包含了文本描述,精彩镜头的图片特写以及比赛时的视频直播和录像等表达形式。多样的表达形式能够使表达内容形象而富于表现力和生动力,方便读者了解。过去的研究工作主要集中在基于内容的多媒体检索上[5]。在这个检索阶段,许多方法都集中在单一媒体检索上,如文本检索[6,7,8]、图像检索[9,10]、音频检索[11,12]、视频检索[13,14,15,16]等。然而这些研究工作忽视了两种以上模态数据之间复杂的相关性,对于跨模态检索任务难以高效灵活处理。
跨媒体数据也叫跨模态数据,这类数据源跨越数据类型,来自不同时间和空间,从不同的方面描述同一个具象。譬如,如图 2-1 所示,世界乒乓球锦标赛中,包含了文本描述,精彩镜头的图片特写以及比赛时的视频直播和录像等表达形式。多样的表达形式能够使表达内容形象而富于表现力和生动力,方便读者了解。过去的研究工作主要集中在基于内容的多媒体检索上[5]。在这个检索阶段,许多方法都集中在单一媒体检索上,如文本检索[6,7,8]、图像检索[9,10]、音频检索[11,12]、视频检索[13,14,15,16]等。然而这些研究工作忽视了两种以上模态数据之间复杂的相关性,对于跨模态检索任务难以高效灵活处理。
2.2 主流跨媒体研究方法
2.2.1 基于公共空间学习方法
一种直观的方式就是统一表征,公共空间学习方法(COMMON SPACE LEARNING,简称 CSL)方法即学习一个公共空间的方法。通过把不同的媒体数据从各自独立的特征空间映射到该空间中,然后在共享子空间中度量二者之间的相关性。本节将分别从基础方法、基本模型、建模、空间形式等方面介绍七类公共空间学习方法:
2.2.1 基于公共空间学习方法
一种直观的方式就是统一表征,公共空间学习方法(COMMON SPACE LEARNING,简称 CSL)方法即学习一个公共空间的方法。通过把不同的媒体数据从各自独立的特征空间映射到该空间中,然后在共享子空间中度量二者之间的相关性。本节将分别从基础方法、基本模型、建模、空间形式等方面介绍七类公共空间学习方法:
(1)传统的统计相关分析方法[17,18,19,20]是常用的空间学习方法的基本范式和基础,主要通过优化统计值来学习公共空间的线性投影矩阵。
在基本模型上,(2)基于 DNN 的方法[21,22,23,24]以深度神经网络为基本模型,旨在利用其强大的抽象能力进行跨媒体相关学习。
在相关性建模方面,(3)跨媒体图正则化方法[25,26,27,28]采用图模型来表示复杂的跨媒体相关性,(4)度量学习方法[29,30]将跨媒体相关性视为一组相似/不同的约束,以及(5)学习排序方法[31,32,33,34]将关注跨媒体排序信息作为其优化目标。
关于公共空间的性质,(6)字典学习方法[35,36,37]生成字典,学习的公共空间用于跨媒体数据的稀疏系数,(7)跨媒体哈希方法[38,39,40,41]旨在学习公共汉明空间以加速检索。
............................
在基本模型上,(2)基于 DNN 的方法[21,22,23,24]以深度神经网络为基本模型,旨在利用其强大的抽象能力进行跨媒体相关学习。
在相关性建模方面,(3)跨媒体图正则化方法[25,26,27,28]采用图模型来表示复杂的跨媒体相关性,(4)度量学习方法[29,30]将跨媒体相关性视为一组相似/不同的约束,以及(5)学习排序方法[31,32,33,34]将关注跨媒体排序信息作为其优化目标。
关于公共空间的性质,(6)字典学习方法[35,36,37]生成字典,学习的公共空间用于跨媒体数据的稀疏系数,(7)跨媒体哈希方法[38,39,40,41]旨在学习公共汉明空间以加速检索。
............................
3.1 引言 ........................... 11
3.2 MMSES 的跨媒体检索框架 ......................... 12
第四章 基于图像特征的嵌入联合降维空间方法 ..................................... 25
4.1 引言 ...................................... 25
4.2 算法框架 ...................................... 26
第五章 总结与展望 ............................ 35
5.1 研究内容总结 .................................. 35
5.2 下一步工作 ........................ 36
第四章 基于图像特征的嵌入联合降维空间方法
4.1 引言
图像特征相对于文本特征来讲,具有更多维度的属性,比如色彩、图形结构、纹路脉络和透视关系[65]等,因此图像特征在提取过程中往往比文本特征噪音更大,而且维度也远远大于文本特征。图像特征所在的高维矩阵也比文本特征更加稀疏,直接采用高维的图像特征进行训练得到的矩阵映射到低维时非常复杂且是非线性的,这样的矩阵对于一些噪音数据也进行了映射,便导致了过拟合。另外,在高维矩阵中,距离度量也更难准确地进行分类,这也是维数灾难的呈现。因此,可先将图像特征经过降维处理,去除图像特征中的噪音,减少冗余信息,然后再将其与文本特征进行相关性分析,从而提高跨媒体检索效率。图像特征的维度相对较高,经此处理不仅可以使矩阵维度减少,对于特征分布和噪音去除也有很好的效果。
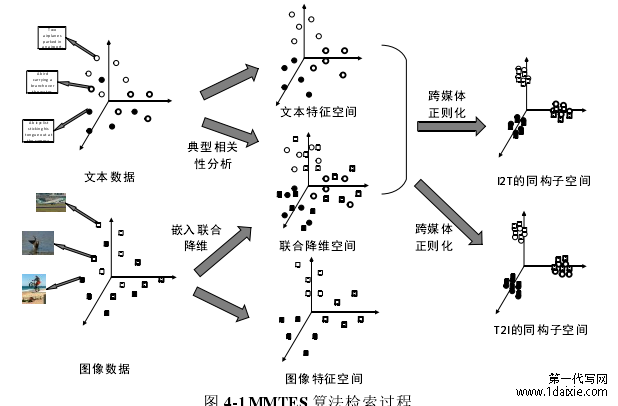
针对上述问题,本章提出了基于图像特征的嵌入联合降维空间算法(MMTES)。图 4-1展示了本文提出的方法框架。具体来说,本文用 PCA 算法解决图像特征的全局优化,用LLE 算法解决图像特征的局部优化,两者联合优化图像特征,组成嵌入联合降维空间。然后将嵌入联合降维空间和文本特征通过距离保持投影映射到高层语义矩阵,以此来完成跨媒体检索。
...........................
第五章 总结与展望
5.1 研究内容总结
跨媒体数据也叫跨模态数据,这类数据源跨越数据类型,来自不同时间和空间,从不同的方面描述同一个具象。跨媒体检索的主要任务是判断不同模态的数据是否表示同一个语义。跨媒体检索面向大数据应用和网络空间安全等国家战略需求,多媒体内容理解技术及其应用对于有害信息识别、智能医疗、热点事件分析、多模态数据利用和军事战略分析等领域具有重要意义。本文回顾了跨媒体检索的发展过程,对大量跨媒体检索及其相关领域文献进行归纳总结,系统性地阐述了跨媒体检索的概念、方法、数据集、研究进度等,期待吸引和帮助更多研究人员更好地参与到跨媒体检索方向的研究中来。
本文基于公共空间方法,提出嵌入空间特征表示思想。本文建立了一个处于底层特征和高级语义中间的中间空间,通过将底层特征进行合理优化得到的嵌入空间更具有判别性,使得检索结果更加准确。不仅如此,本文在细粒度查询工作中对底层的多模态数据特征通过一定的方式进行优化,形成一个嵌入空间表示,然后从嵌入文本增强空间投影,得到更有效的目标矩阵。在该嵌入空间中,不仅可以进行更准确的跨媒体检索任务,还可进行细粒度检索等研究。
5.1 研究内容总结
跨媒体数据也叫跨模态数据,这类数据源跨越数据类型,来自不同时间和空间,从不同的方面描述同一个具象。跨媒体检索的主要任务是判断不同模态的数据是否表示同一个语义。跨媒体检索面向大数据应用和网络空间安全等国家战略需求,多媒体内容理解技术及其应用对于有害信息识别、智能医疗、热点事件分析、多模态数据利用和军事战略分析等领域具有重要意义。本文回顾了跨媒体检索的发展过程,对大量跨媒体检索及其相关领域文献进行归纳总结,系统性地阐述了跨媒体检索的概念、方法、数据集、研究进度等,期待吸引和帮助更多研究人员更好地参与到跨媒体检索方向的研究中来。
本文基于公共空间方法,提出嵌入空间特征表示思想。本文建立了一个处于底层特征和高级语义中间的中间空间,通过将底层特征进行合理优化得到的嵌入空间更具有判别性,使得检索结果更加准确。不仅如此,本文在细粒度查询工作中对底层的多模态数据特征通过一定的方式进行优化,形成一个嵌入空间表示,然后从嵌入文本增强空间投影,得到更有效的目标矩阵。在该嵌入空间中,不仅可以进行更准确的跨媒体检索任务,还可进行细粒度检索等研究。
本文在研究过程中发现,图像模态的特征在提取过程中容易产生语义鸿沟,而在语义空间中,文本模态的特征空间分布往往比视觉特征的空间分布更为明显。基于此,本文提出了基于模态依赖的嵌入语义增强空间(MMSES)方法,通过共享子空间将其转换成相应的视觉特征,提高视觉特征的表示能力。具体来说,我们首先利用线性判别分析(LDA)将文本信息投射到中义语义增强空间,增强文本模态的判别能力。然后,我们通过固定距离投影建立映射矩阵,将增强的判别能力转化为视觉特征。在检索过程中,本文提出模态依赖方法,针对不一样的跨媒体检索任务学习不一样的算法模型。模态依赖不同于以往学习一对投影的方法,以图像和文本之间的相互检索为例,它通过学习将图像到文本检索(I2T)和文本到图像检索(T2I)从其原始特征空间投影到两个公共潜在子空间来学习两组投影。如果两个任务同时学习,得到的公共子空间是 I2T 和 T2I 共有的性能均衡的子空间,这对于某一个检索任务性能通常不是最优的。例如,在 I2T 中,通常认为在图像语义空间中准确表示查询比检索文本更重要。如果对查询的语义判断错误,则检索相关文本将更加困难。如果单独针对检索图像任务,则可以将图像单独投影到其语义空间中。此时,在没有文本干扰的情况下,对图像的语义理解是最优的。当图像语义被理解时,检索到的数据更加准确,从而提高了跨媒体检索的准确性。
参考文献(略)
参考文献(略)