第一章 绪论
第一节 研究背景及意义
一、研究背景
随着现代社会的发展,人们逐渐从“生存式生活”转变为“享受式生活”,旅游业逐渐成为中国最大的经济市场,因此国内的酒店行业也获得了良好的发展空间。根据 2018 年中国统计年鉴显示,2017 年我国第三产业国内生产总值高达 427031.5 亿元,同比增长11.4%,占 2018 年国内生产总值的 51.63%,其中,住宿与餐饮业创造的国内生产总值达到 14594.1 亿元,在第三产业国内生产总值中占比达到 34.15%。同年,我国接待入境旅客 13948.2 万人次,相较于 2016 年同比增长 0.75%,国内旅客 50 亿人次,相较于 2016年同比增长 12.61%。伴随着第三产业的快速发展和旅游人数的迅猛增长,国内酒店数量也越来越多。2017 年住宿业法人企业个数为 19780 个,相较于 2013 年的 18437 个,五年间增长了 7.28%;2017 年住宿业客房数为 393.2 万间,相较于 2013 年 265.5 间,五年间客房数增长了 48.10%。酒店行业在快速发展的同时面临的竞争也越来越激烈。
第一节 研究背景及意义
一、研究背景
随着现代社会的发展,人们逐渐从“生存式生活”转变为“享受式生活”,旅游业逐渐成为中国最大的经济市场,因此国内的酒店行业也获得了良好的发展空间。根据 2018 年中国统计年鉴显示,2017 年我国第三产业国内生产总值高达 427031.5 亿元,同比增长11.4%,占 2018 年国内生产总值的 51.63%,其中,住宿与餐饮业创造的国内生产总值达到 14594.1 亿元,在第三产业国内生产总值中占比达到 34.15%。同年,我国接待入境旅客 13948.2 万人次,相较于 2016 年同比增长 0.75%,国内旅客 50 亿人次,相较于 2016年同比增长 12.61%。伴随着第三产业的快速发展和旅游人数的迅猛增长,国内酒店数量也越来越多。2017 年住宿业法人企业个数为 19780 个,相较于 2013 年的 18437 个,五年间增长了 7.28%;2017 年住宿业客房数为 393.2 万间,相较于 2013 年 265.5 间,五年间客房数增长了 48.10%。酒店行业在快速发展的同时面临的竞争也越来越激烈。
随着近年来互联网使用量的突飞猛进,其技术的发展也呈现出百花齐放的态势,据中国互联网信息中心(CNNIC)在 2019 年 2 月 28 日发表的第 43 次《中国互联网络发展状况统计报告》显示,截止 2018 年底,中国使用互联网总人数已达到了惊人的 8.29亿,接近全中国人口的 60%,较 2017 年上升了近 4%,全年新增网友高达 5600 万,增加比例接近 3%。截止 2018 年底,中国手机上网人数达到 8.17 亿,全年新增手机上网用户约为 6400 万,同比增长 8.5%。手机上网覆盖率由 2017 年的 97.5%上升至 2018 年的98.6%,正在朝着全民全网 100%覆盖的目标不懈前进中。
...................
第二节 研究思路与研究内容
一研究思路
首先,通过了解线上旅行社到酒店发展的现状,发现其中存在的问题,根据已有文献所提供的研究方法和研究思路,汇总整理了当前在文本情感分类和主题挖掘两个方面的研究成果,为之后的研究做好前期准备工作。
接着,确定选取受众最广的经济型酒店作为分析研究对象,爬取携程网站杭州地区如家酒店和汉庭酒店的用户评论文本作为分析数据。对爬取到的文本进行数据清洗,保留含有信息量且对主题挖掘有效的文本数据。之后将 NTUSD 词典与 HowNet 词典的情感词合并,并结合爬取到的文本数据,构建酒店领域情感词典,利用该词典对爬取到的酒店评论进行分词。将分词后的文本作为输入变量,对 Word2vec 模型进行训练,构建词向量以用于下一步情感分类。情感分类使用 TextCNN 卷积神经网络模型,将词向量作为输入变量进行模型训练,通过调整参数设定获得最优的模型用于文本分类。
最后将所有分类好的文本数据作为输入变量,训练 LDA 主题模型,通过主题挖掘及可视化展示,全面了解两家经济型快捷酒店各自的优势和劣势,通过合理分析,提出相应的建议。
.......................
第二章 情感分类与主题模型挖掘技术理论及方法阐述
第一节 文本预处理
一、中文分词
在中文中,词是最小的语言单位。中文分词是文本预处理的首要步骤,其意思是将中文的一句话按照一定的规范分割成单独的词,这也是中文文本处理较英文更复杂也更具挑战性的地方。在英文语句中,例如”I like playing basketball ”,其本身自带空格符以起到分词的效果,这在中文语句中是不存在的,中文只有标点符号对语句进行断句。因此需要利用中文分词的方法对中文语句进行识别,方法主要有以下四类:
基于理解的分词方法。该方法又被称作人工智能分词法,其基本思想就是根据人对句子理解的过程,将句法和语义的分析作为分词过程中的考虑条件来处理存在的歧义现象。就该分析方法而言,主要分为两部分,总控部分负责控制各个子系统,并协调各个子系统之间的工作,相当于人类的大脑。而分词部分作为子系统,主要用于判别词语是否有歧义。目前主流方法有两种,分别为神经网络和专家系统。
第三章 酒店评论短文本情感倾向性分析 .................................. 34...................
第二节 研究思路与研究内容
一研究思路
首先,通过了解线上旅行社到酒店发展的现状,发现其中存在的问题,根据已有文献所提供的研究方法和研究思路,汇总整理了当前在文本情感分类和主题挖掘两个方面的研究成果,为之后的研究做好前期准备工作。
接着,确定选取受众最广的经济型酒店作为分析研究对象,爬取携程网站杭州地区如家酒店和汉庭酒店的用户评论文本作为分析数据。对爬取到的文本进行数据清洗,保留含有信息量且对主题挖掘有效的文本数据。之后将 NTUSD 词典与 HowNet 词典的情感词合并,并结合爬取到的文本数据,构建酒店领域情感词典,利用该词典对爬取到的酒店评论进行分词。将分词后的文本作为输入变量,对 Word2vec 模型进行训练,构建词向量以用于下一步情感分类。情感分类使用 TextCNN 卷积神经网络模型,将词向量作为输入变量进行模型训练,通过调整参数设定获得最优的模型用于文本分类。
最后将所有分类好的文本数据作为输入变量,训练 LDA 主题模型,通过主题挖掘及可视化展示,全面了解两家经济型快捷酒店各自的优势和劣势,通过合理分析,提出相应的建议。
.......................
第二章 情感分类与主题模型挖掘技术理论及方法阐述
第一节 文本预处理
一、中文分词
在中文中,词是最小的语言单位。中文分词是文本预处理的首要步骤,其意思是将中文的一句话按照一定的规范分割成单独的词,这也是中文文本处理较英文更复杂也更具挑战性的地方。在英文语句中,例如”I like playing basketball ”,其本身自带空格符以起到分词的效果,这在中文语句中是不存在的,中文只有标点符号对语句进行断句。因此需要利用中文分词的方法对中文语句进行识别,方法主要有以下四类:
基于理解的分词方法。该方法又被称作人工智能分词法,其基本思想就是根据人对句子理解的过程,将句法和语义的分析作为分词过程中的考虑条件来处理存在的歧义现象。就该分析方法而言,主要分为两部分,总控部分负责控制各个子系统,并协调各个子系统之间的工作,相当于人类的大脑。而分词部分作为子系统,主要用于判别词语是否有歧义。目前主流方法有两种,分别为神经网络和专家系统。
基于字符串匹配的分词方法(机械分词法)。该方法的构建与前一种不同,首先需要自主建立一个词典,该词典要求尽可能囊括更多的中文词汇,然后进行字符串匹配,匹配时既可以正向扫描也可以选择逆向扫描,当字符串与词典中的词匹配成功时,便将该词语提取出来。
基于统计的分词方法。该方法又被称作无字典分词法,其基本思想认为词是一种较为稳定的组合,当两个字经常以邻近的方式出现时,依据该方法有大概率可以将这两个字组合成一个词。通过计算邻近字之间的互现信息,其结果越高表示邻近字的结合紧密度越强,反之则越弱。另外还需要设置一个阈值,如果计算的互现信息高于设定的阈值,则将其视为一个词。
基于语义的分词方法。该方法主要考虑语义信息的影响,在自然语言中存在许多信息,但要想得到这些信息就需要先对自然语言进行处理。其常用的算法主要包括扩充转移网络。
.......................
第二节 情感词典
情感词典的主要用途是对文本进行无监督的情感分类,网络上主流的统计词典有台湾大学自然语言处理实验室提供的简体中文情感词典(NTUSD)、知网(HowNet)发布的情感词典、张伟等主编的《学生褒贬义词典》以及 GI(General Inquirer)英文情感词典。其中 NTUSD 词典中有积极情感词 2810 个和消极情感词 8272 个。HowNet 词典相比 NTUSD 词典更为丰富,其不仅包含积极情感词和消极情感词,还囊括了各种程度级别词语,将上述词语合并后,得到积极情感词 4366 个和消极情感词 4370 个。褒贬义词典中包含积极情感词 728 个和消极情感词 933 个。通过观察统计词典后发现,这些统计词典中存在大量普通常见的情感词,并且没有对词的情感极性值进行标注,由于担心情感词的普适性不足而导致文本情感分类的结果较差,因此一般会通过构造特定领域词典的方式来改进。在构造领域词典的过程中,通常需要计算情感词的情感值,计算方法主要有两种:基于知网信息和基于点互信息 PMI。
Bag-of-words 模型即词袋模型,简单来说就是通过数学向量的方法对文本进行抽象表示。其前提假定文本中各个词语是彼此独立、互不相关的,每个词的出现不依赖于前后文中的其他词语。与此同时,词袋模型不关心文本语句中的语序语法问题,只是将文本看做词语的集合,因此显著降低了模型的复杂度。
基于统计的分词方法。该方法又被称作无字典分词法,其基本思想认为词是一种较为稳定的组合,当两个字经常以邻近的方式出现时,依据该方法有大概率可以将这两个字组合成一个词。通过计算邻近字之间的互现信息,其结果越高表示邻近字的结合紧密度越强,反之则越弱。另外还需要设置一个阈值,如果计算的互现信息高于设定的阈值,则将其视为一个词。
基于语义的分词方法。该方法主要考虑语义信息的影响,在自然语言中存在许多信息,但要想得到这些信息就需要先对自然语言进行处理。其常用的算法主要包括扩充转移网络。
.......................
第二节 情感词典
情感词典的主要用途是对文本进行无监督的情感分类,网络上主流的统计词典有台湾大学自然语言处理实验室提供的简体中文情感词典(NTUSD)、知网(HowNet)发布的情感词典、张伟等主编的《学生褒贬义词典》以及 GI(General Inquirer)英文情感词典。其中 NTUSD 词典中有积极情感词 2810 个和消极情感词 8272 个。HowNet 词典相比 NTUSD 词典更为丰富,其不仅包含积极情感词和消极情感词,还囊括了各种程度级别词语,将上述词语合并后,得到积极情感词 4366 个和消极情感词 4370 个。褒贬义词典中包含积极情感词 728 个和消极情感词 933 个。通过观察统计词典后发现,这些统计词典中存在大量普通常见的情感词,并且没有对词的情感极性值进行标注,由于担心情感词的普适性不足而导致文本情感分类的结果较差,因此一般会通过构造特定领域词典的方式来改进。在构造领域词典的过程中,通常需要计算情感词的情感值,计算方法主要有两种:基于知网信息和基于点互信息 PMI。
Bag-of-words 模型即词袋模型,简单来说就是通过数学向量的方法对文本进行抽象表示。其前提假定文本中各个词语是彼此独立、互不相关的,每个词的出现不依赖于前后文中的其他词语。与此同时,词袋模型不关心文本语句中的语序语法问题,只是将文本看做词语的集合,因此显著降低了模型的复杂度。
与 NNLM 相同,Word2vec 也是利用神经网络进行模型训练,通过不断调优对训练数据进行拟合,将语料中的词汇映射到自定义的 K 维词向量下。因此在文本挖掘的问题中一般采用向量或矩阵形式进行计算,最终在保证语义对前提下,将计算机难以处理的文本用合理的方式进行表示。
.................................
.................................
第一节 数据说明与数据预处理 ................................ 34
一、数据来源说明 ................................ 34
二、数据预处理 .................................. 34
第四章 积极评论与消极评论文本主题挖掘 ..................................... 46
第一节 基于 LDA 积极评论与消极评论主题挖掘 .................................. 46
一、LDA 参数设定 ............................................ 46
二、LDA 主题挖掘结果展示 ..................................... 47
第五章 研究结论与建议 ................................................ 53
第一节 研究结论 ............................................... 53
一、情感倾向性分析结论 ................................. 53
二、积极评论与消极评论主题挖掘结论 .............................. 53
第四章 积极评论与消极评论文本主题挖掘
第一节 基于 LDA 积极评论与消极评论主题挖掘
一、LDA 参数设定
以如家积极情感数据集为例。首先对上文利用卷积神经网络分类好的文本进行分词,将酒店评论文本全部分解为单词(token),然后利用 python 中 scikit-learn 向量化工具CounterVectorizer ,对于文档集合进行向量化。接着调用 scikit-learn 工具包中的LatentDirichletAllocation 函数,经过参数调整结合后文的可视化,确定主题数量为 4,经过最大 40 轮次的迭代过程后,获得初步的主题识别结果。CounterVectorizer 和LatentDirichlet-Allocatio 的参数设定如表所示。
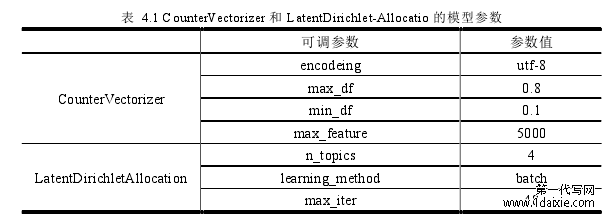
一、LDA 参数设定
以如家积极情感数据集为例。首先对上文利用卷积神经网络分类好的文本进行分词,将酒店评论文本全部分解为单词(token),然后利用 python 中 scikit-learn 向量化工具CounterVectorizer ,对于文档集合进行向量化。接着调用 scikit-learn 工具包中的LatentDirichletAllocation 函数,经过参数调整结合后文的可视化,确定主题数量为 4,经过最大 40 轮次的迭代过程后,获得初步的主题识别结果。CounterVectorizer 和LatentDirichlet-Allocatio 的参数设定如表所示。
.........................
第五章 研究结论与建议
第一节 研究结论
本文爬取携程网站杭州地区如家和汉庭两家经济型快捷酒店的评论,构建自定义酒店领域情感词典,对原始语料进行分词并构建词向量。将带有情感标签评论的词向量作为输入变量,对 TextCNN 卷积神经网络进行训练,利用训练好的网络模型对未带有情感标签的评论进行情感分类。最后分别对两家酒店各自的积极评论和消极评论进行 LDA主题挖掘,利用 LDAvis 可视化结果,分析两家酒店各自的优势和劣势。得到结论如下。 一、情感倾向性分析结论
通过 TextCNN 卷积神经网络的情感倾向性分析,得到以下结论。
第一,如家酒店和汉庭酒店的消极评论占比都达到 20%以上,说明客户对两家酒店感到不满意的因素较多。如家酒店的情感结果数值总体得分较高,75%以上的评论都为积极评论。和如家酒店相比,汉庭酒店消极评论的占比更高,接近 27%,说明和如家酒店相比汉庭酒店客户对其更加不满意,汉庭酒店需要完善改进的地方也更多。
第二,如家酒店和汉庭酒店积极评论和消极评论中的高频词较为一致,都大致反映了客户对酒店的整体印象。积极评论中的高频词都是“好”,“不错”等,消极评论中反映房间问题较多,酒店需要加强房间内部管理和服务。
二、积极评论与消极评论主题挖掘结论
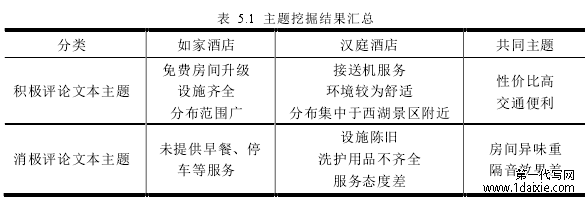
通过消极评论和积极评论文本主题挖掘,利用关键词估计主题含义,结合具体评论信息,可以将两家酒店最终的结果总结如表 5.1。
参考文献(略)