第一章 绪论
1.1 研究工作的背景与意义
随着计算机技术的不断发展,互联网应用的不断普及,计算机为我们带来了强大的计算能力。为了提升生产力以及管理能力,在过去的几十年中,各行各业在信息化建设中的投入逐年增加[3],各个企业的信息化日益完善[5]。
随着信息化的完善,整个信息化系统在承担着越来越重要的作用,业务人员对于信息化系统的要求越来越高,信息化系统能否稳定可靠的运行关系着企业的日常生产和业务能否正常展开,因此信息化系统的稳健性显得尤为重要和突出[6]。
另一方面信息化系统也变得越来越庞大越来越复杂,IT 系统出现故障的概率也变得越来越大[8],同时因为信息化系统故障导致信息化系统不可用而产生的损失也会越来越大[11],IT 系统使用人员对 IT 系统故障处理的时效要求也越来越高。
而随着网络和应用系统迅速增加,信息管理的难度越来越大,系统维护需要越来越多的人员,操作维护人员的技术水平要求也越来越高,技术人员的综合素质也要求越来越强。
在过去通过人工进行 IT 系统的运维,往往是 IT 系统发生故障,IT 系统可用性受到影响,使用 IT 系统的业务人员发现了系统异常后向 IT 运维人员报告故障,之后 IT 运维人员才去排查故障的原因,效率低下,系统不可用的时间较长,对企业的损失也较大。
1.1 研究工作的背景与意义
随着计算机技术的不断发展,互联网应用的不断普及,计算机为我们带来了强大的计算能力。为了提升生产力以及管理能力,在过去的几十年中,各行各业在信息化建设中的投入逐年增加[3],各个企业的信息化日益完善[5]。
随着信息化的完善,整个信息化系统在承担着越来越重要的作用,业务人员对于信息化系统的要求越来越高,信息化系统能否稳定可靠的运行关系着企业的日常生产和业务能否正常展开,因此信息化系统的稳健性显得尤为重要和突出[6]。
另一方面信息化系统也变得越来越庞大越来越复杂,IT 系统出现故障的概率也变得越来越大[8],同时因为信息化系统故障导致信息化系统不可用而产生的损失也会越来越大[11],IT 系统使用人员对 IT 系统故障处理的时效要求也越来越高。
而随着网络和应用系统迅速增加,信息管理的难度越来越大,系统维护需要越来越多的人员,操作维护人员的技术水平要求也越来越高,技术人员的综合素质也要求越来越强。
在过去通过人工进行 IT 系统的运维,往往是 IT 系统发生故障,IT 系统可用性受到影响,使用 IT 系统的业务人员发现了系统异常后向 IT 运维人员报告故障,之后 IT 运维人员才去排查故障的原因,效率低下,系统不可用的时间较长,对企业的损失也较大。
如果通过 IT 运维监控系统,将整个 IT 系统进行统一的管理,通过监控一些代表系统健康度的指标来提前发现 IT 系统的异常,那么可以在业务人员感知到系统不可用之前快速准确的处理掉 IT 系统异常,减少企业的损失。
...................
第三章 系统需求分析........................................15...................
1.2 IT 运维监控系统的国内外研究历史与现状
IT 运维监控伴随着 IT 系统的建设而发展,最早在 20 世纪 80 年代的时候,英国商务部发布了 ITIL[7](信息技术基础架构库,Information Technology InfrastructureLibrary),作为英国政府 IT 部门的最佳实践指南,ITIL 发展不久,就在英国的各个私立企业中得到了推广,然后从英国慢慢的发展到欧美国家去。
ITIL 作为一个融合了最佳 IT 实践,用于 IT 部门提供高质量运维服务的服务标准,可以帮助企事业单位满足日益增长的对 IT 服务的要求。通过实施 ITIL,可以改进 IT 运维的效率,可以对 IT 运维的运营效率提升 25%以上。通过行业专家、IT 部门实施者的共同努力,
IT 运维监控伴随着 IT 系统的建设而发展,最早在 20 世纪 80 年代的时候,英国商务部发布了 ITIL[7](信息技术基础架构库,Information Technology InfrastructureLibrary),作为英国政府 IT 部门的最佳实践指南,ITIL 发展不久,就在英国的各个私立企业中得到了推广,然后从英国慢慢的发展到欧美国家去。
ITIL 作为一个融合了最佳 IT 实践,用于 IT 部门提供高质量运维服务的服务标准,可以帮助企事业单位满足日益增长的对 IT 服务的要求。通过实施 ITIL,可以改进 IT 运维的效率,可以对 IT 运维的运营效率提升 25%以上。通过行业专家、IT 部门实施者的共同努力,
ITIL 作为 ISO/IEC 2000 的基础,已经成为了 IT 运维领域内事实上的国际标准,目前 ITIL 已经发展到了 ITIL V4 标准。
2007 年由 ASG Software Solutions、惠普、IBM 和微软等公司组成的CMDBf(CMDB 联合工作组)组织提出了 CMDB[8](配置管理数据库,configurationmanagement database)标准架构,CMDB 是配置管理过程的基本组成部分,通过CMDB 可以把数据集成起来,纳入 CMDB 中,CMDB 贯穿 ITIL 全过程。
2007 年由 ASG Software Solutions、惠普、IBM 和微软等公司组成的CMDBf(CMDB 联合工作组)组织提出了 CMDB[8](配置管理数据库,configurationmanagement database)标准架构,CMDB 是配置管理过程的基本组成部分,通过CMDB 可以把数据集成起来,纳入 CMDB 中,CMDB 贯穿 ITIL 全过程。
基于 CMDB,以 IBM 和 HP 为代表的一系列商业公司推出了商业版本的 IT 运维解决方案。其中,IBM 公司推出了 Tivoli 系列软件,Tivoli 是一个功能强大的运维监控组件,支持对主机、网络、业务的监控,可以智能的对基础设备进行监控,对 IT 运维实施提供了一些列整体的解决方案[9]。在 2012 年,IBM 的 Tivoli 系列软件占领了 IT 运维市场 18%的市场。HP 公司于 2007 年推出了 ServiceDesk 和Openview 等 IT 运维产品和解决方案[10],通过 Openview 可以对 IT 系统中的主机、网络、业务进行监控,尤其是对于 HP Unix 设备的支持比较好。在国外开源界,2012 年开源了 zabbix2.0.2,zabbix 是一个基于 WEB 的分布式 IT 运维监控开源方案,通过 zabbix 可以通过多种协议对服务器硬件、网络服务进行监控,收集监控数据。目前 zabbix 是世界范围内使用最广泛的开源 IT 运维监控系统。
..................
第二章 相关技术简介
2.1 数据采集相关技术简介
IT 运维监控系统支持对多种主机设备、网络设备、数据库、中间件的监控。对于支持 SNMP 协议的主机设备、网络设备,系统主要通过 SNMP 协议获取设备的相关数据;对于支持 ssh 协议的搭载类 Unix 系统的设备,系统主要是通过 SSH协议连接设备执行命令获取设备相关数据。对于数据库类可以通过 JDBC 协议
2.1.1 SNMP 采集技术介绍
第二章 相关技术简介
2.1 数据采集相关技术简介
IT 运维监控系统支持对多种主机设备、网络设备、数据库、中间件的监控。对于支持 SNMP 协议的主机设备、网络设备,系统主要通过 SNMP 协议获取设备的相关数据;对于支持 ssh 协议的搭载类 Unix 系统的设备,系统主要是通过 SSH协议连接设备执行命令获取设备相关数据。对于数据库类可以通过 JDBC 协议
2.1.1 SNMP 采集技术介绍
SNMP(简单网络管理协议)是一个处于 TCP/IP 应用层的协议,SNMP 在 1988年制定,被 IAB(Internet 体系结构委员会)采纳为一个短期的网络的管理解决方案。SNMP 是一个非常简单的协议,基于 SNMP 的简单性,在 Internet 时代 SNMP得到了蓬勃的发展,在 1992 年,发表了 V2 版本的 SNMP,在 V2 版本的 SNMP中主要是针对 SNMP 在 V1 中比较薄弱的安全性进行了增强,对 V1 中的功能性进行了补充强化。发展到现在 SNMP 已经发展到了 V3 版本。一套完整的 SNMP 协议主要有三方面组成:
SNMP 报文协议、管理信息库(MIB)、管理信息结构(SMI)。SNMP 通过管理站与 SNMP 代理进行交互,通过 SNMP MIB 定义的各种信息进行查询获取信息。整个 SNMP 协议的结构如图 2-1[17] 所示。
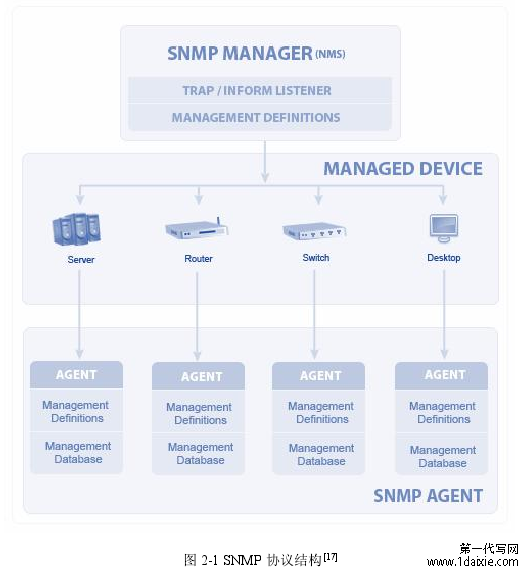
...................
...................
2.2 告警相关技术简介
一个运维监控系统很重要的一个部分就是告警,在故障处于萌芽状态,或者影响范围很小的时候,及时发现故障并报告给相关的运维人员进行处理,最小化的减少故障可能造成的损失。同时,运维人员在接收到告警时,接收到的告警信息里面包含了明确的错误信息,运维人员可以很容易的定位到具体的告警位置,从而很快的完成对告警的处理。
对于被监控设备来说,它有很多指标来反映系统的健康状态,当这些指标的值异常的时候,很大可能系统即将或者已经发生故障,从而被用户感知到。因此实现告警的一个手段就是,定义出这些能够反映系统健康状态的指标,并且定义好这些指标的异常判定条件,当监控系统监控到某项指标的值处于异常状态时,发出告警。同时,由于整个被监控系统里面的各个被监控单元会存在各种关联,所以一个告警可能会引起大量的告警,为了帮助运维人员快速定位告警原因,不被海量的告警所淹没,所以需要对这些告警进行压缩。因此告警主要涉及到三个方面:定义指标、判断告警、告警压缩。
....................
一个运维监控系统很重要的一个部分就是告警,在故障处于萌芽状态,或者影响范围很小的时候,及时发现故障并报告给相关的运维人员进行处理,最小化的减少故障可能造成的损失。同时,运维人员在接收到告警时,接收到的告警信息里面包含了明确的错误信息,运维人员可以很容易的定位到具体的告警位置,从而很快的完成对告警的处理。
对于被监控设备来说,它有很多指标来反映系统的健康状态,当这些指标的值异常的时候,很大可能系统即将或者已经发生故障,从而被用户感知到。因此实现告警的一个手段就是,定义出这些能够反映系统健康状态的指标,并且定义好这些指标的异常判定条件,当监控系统监控到某项指标的值处于异常状态时,发出告警。同时,由于整个被监控系统里面的各个被监控单元会存在各种关联,所以一个告警可能会引起大量的告警,为了帮助运维人员快速定位告警原因,不被海量的告警所淹没,所以需要对这些告警进行压缩。因此告警主要涉及到三个方面:定义指标、判断告警、告警压缩。
....................
3.1 总体需求分析.......................................16
3.2 设备监控的需求分析............................................17
第四章 系统设计....................................................24
4.1 系统总体设计....................................24
4.1.1 系统设计原则.................................24
4.1.2 技术选型................................25
第五章 IT 运维监控系统的实现.....................................38
5.1 系统关键子模块的实现..............................38
5.1.1 设备管理的实现.....................................38
5.1.2 指标管理的实现...............................41
第五章 IT 运维监控系统的实现
5.1 系统关键子模块的实现
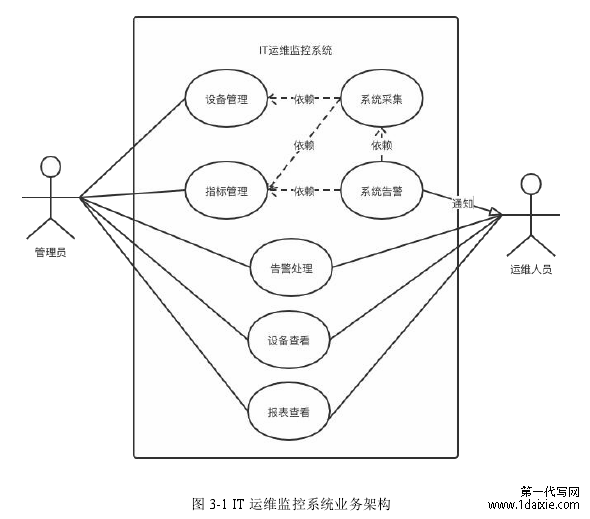
在前面的业务架构图(图 3-2)中,我们将 IT 运维监控系统分成了三层。分别是设备监控、系统告警、可视化。
设备监控是整个 IT 运维监控系统的基石,设备监控分成设备管理、指标管理、调度采集三个子模块。通过设备管理,可以将 IT 系统中的设备或系统作为被监控单元统一添加进行 IT 运维管理系统中,在 IT 运维管理系统中进行统一的管理。指标管理是为每一个设备添加能够反映 IT 系统健康度的指标进行监控。调度采集是对添加的指标,按照设定的采集周期,定期去进行指标数据的采集,用来判断系统的健康状态、告警、可视化。
系统告警是 IT 运维监控系统的重要组成部分,通过告警可以在系统健康状态处于异常情况时,让运维人员第一时间收到通知,并且快速定位到引起系统异常的原因,加速运维人员处理故障的效率。同时由于系统的关联性,一次系统异常的发生可能同时触发多条告警,因此还需要对告警进行压缩。
.........................
第六章 全文总结与展望
6.1 全文总结
本文首先从 IT 系统的重要性以及 IT 系统必然会出现故障引出了 IT 运维的概念;之后介绍了传统通过人力进行 IT 运维存在效率较低、人力成本高、故障响应速度慢的问题,阐述了 IT 运维监控系统存在的意义。
从业务角度上讲解了一个 IT 运维监控系统的核心逻辑:定义一系列与 IT 系统健康状况有关的指标,周期的去自动获取这些指标的值,通过判定这些指标值是否处于异常状况来判断整个 IT 系统的健康状态,当发现 IT 系统监控状况处于异常时及时将异常状况通知到对应的 IT 运维人员进行快速的处理,从而保障整个 IT系统的健康运行。
对整个 IT 运维监控系统抽象成了三层:设备监控层、系统告警层、可视化层。在设备监控层中主要是对 IT 系统中的被监控单元进行管理,为被监控单元添加一系列指标,周期性的去采集指标的值;系统告警层主要是当发现指标的采集值处于异常情况时,及时将告警信息准确的通知给对应运维人员,方便运维人员快速处理异常;可视化层是通过各种对人友好的交互界面展示整个 IT 系统的运行状况。整篇论文给出了一个 IT 运维监控系统的完整实现,尤其是介绍了如何通过分布式、集群、大数据的相关技术解决超大规模的 IT 系统的监控.
参考文献(略)